
新智元报道
编辑:编辑部
【新智元导读】ChatGPT之类的AI编码工具来势汹汹,Stack Overflow又裁员了!不过,普林斯顿和芝大竟发现,面对真实世界GitHub问题,GPT-4的解决率竟是0%。
Stack Overflow,已经被ChatGPT创飞了!
因为码农大量涌向ChatGPT、Github Copilot,Stack Overflow今天不得已宣布裁员100多人,几乎占员工人数的1/3。

所以,ChatGPT这类AI编码工具,真的要颠覆整个行业了?
不过最近,普林斯顿和芝大的一项研究发现,LLM想要替代码农,其实没那么容易。

论文地址:https://arxiv.org/abs/2310.06770
在2294个GitHub真实问题面前,GPT-4解决随机GitHub问题的通过率,竟然是0%!
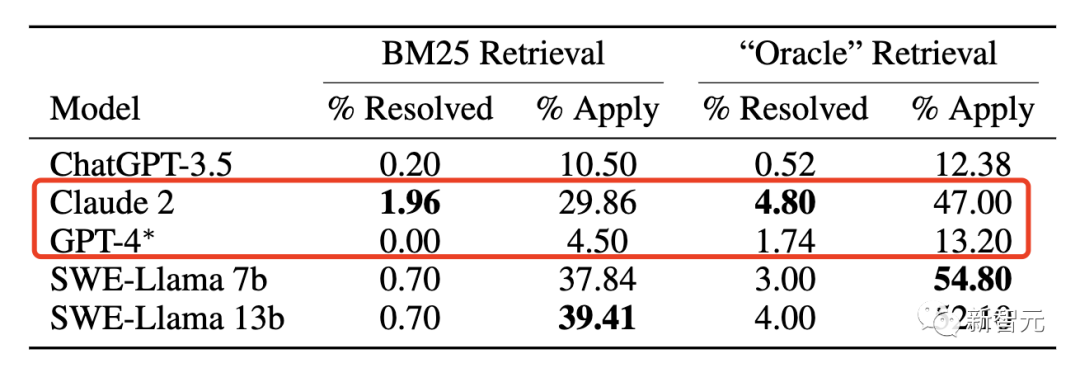
而即使是最佳模型Claude 2,也只能解决其中的1.96%而已。
码农会因为ChatGPT而失业吗?答案是——目前绝对不会。
要么适应,要么灭亡
作为全世界每个开发者最爱的代码辅助网站,Stack Overflow在此前的形势还一片大好,在去年掀起了一场招聘狂潮,整个公司的员工人数都翻了一番,达到了540人。
然而,自从去年11月OpenAI发布了ChatGPT后,一切都变了。

AI聊天机器人提供的帮助,比5年前的论坛帖子更加具体。通过LLM,开发者可以即时更正确切的代码、优化建议,以及每行代码正在执行操作的说明。
虽说LLM提供的答案也并不是100%可靠,但代码具有独特的能力,只需在IDE集成开发环境中进行测试,即可立即验证代码了,这一切都使写代码成为了ChatGPT的理想用例。
因此,Stack Overflow的流量大大减少,ChatGPT、GPT-4驱动的Github Copilot等AI编程工具,都成为了码农的新去处。
今天,CEO Prashanth Chandrasekar宣布,Stack Overflow裁员一百多人,占员工总数的28%。

CEO对于裁员的解释是,宏观经济压力下,Stack Overflow在努力走上盈利之路,不断推出产品创新。
过河拆桥?
ChatGPT给Stack Overflow造成冲击这件事,最大讽刺之处在于,大语言模型的强大能力,很大程度上就是来自像Stack Overflow这样的抓取网站。
大语言模型吸空了这些数据,却不回馈任何东西,如果所有数据源都被迫赶出了这一业务,那时会发生什么?
现在,不少科技公司面前已经存在着迫在眉睫的问题:如果程序员减少,人造数据就会减少。
如果没有最新的数据,怎么训练新的AI模型呢?
想用我们的数据?拿钱来
Stack Overflow当然不能坐以待毙,它选择了两种方式自救——
一是开发自己的AI编码工具OverflowAI,二是直接和OpenAI这样的科技公司寻求合作,因为这些公司会使用Stack Overflow的数据构建AI模型。

据悉,OpenAI正在为ChatGPT开发网络爬虫控制,这样Stack Overflow这样的网站的数据就不会被爬取。
CEO表示,Stack Overflow已经表明了立场:谁想用我们的数据来训练LLM,谁就来付费。
CEO认为,像Stack Overflow这样的网站对于大语言模型的发展至关重要,为了进步,它们需要在新知识上进行训练。

Stack Overflow首席执行官Prashanth Chandrasekar
LLM想取代码农,还早着呢
所以,大语言模型真能取代码农吗?
普林斯顿和芝大团队发现,没那么容易!

在最新论文中,研究人员提出了一种全新框架SWE-bench,以评估大模型在解决2294个GitHub真实问题中的能力。
结果发现,像GPT-4、Claude 2这样领先的大模型,解决实际问题的能力,都不过5%。
再具体点,GPT-4可以解决随机GitHub问题的通过率竟是0%,而最佳模型Claude 2,也只能解决其中的1.96%。
更值得一提的是,在使用BM-25检索每个问题的相关代码文件时,Claude 2编写的补丁中只有23%是有效的(可以用于repo),只有~1%真正解决了问题。
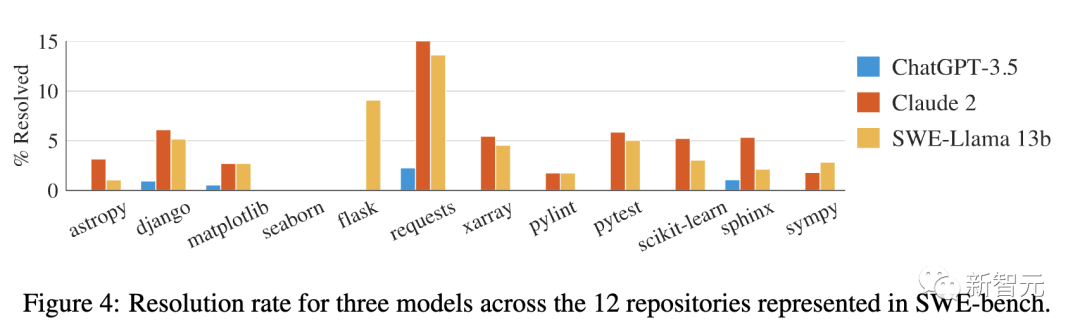
此外,不同的模型,在解决12个流行的Python库问题的性能,也有所差异。
GPT-4大模型取得这样的结果,真是让人大跌眼镜,毕竟许多人都早已将其视为「编程利器」。
但要看清,AI真正的实力,不要被刷榜评分而陷入担忧。
有网友表示,这是对「码农是否因编程而失业」问题的最好的解答。

终于有人为代码模型制作了一个真正的eval数据集,HumEval只是LLM的leetcode面试。我们都知道,这对人类工程师来说是个错误的衡量标准。不到4%听起来是对的,因为大模型离完全自主还很远。
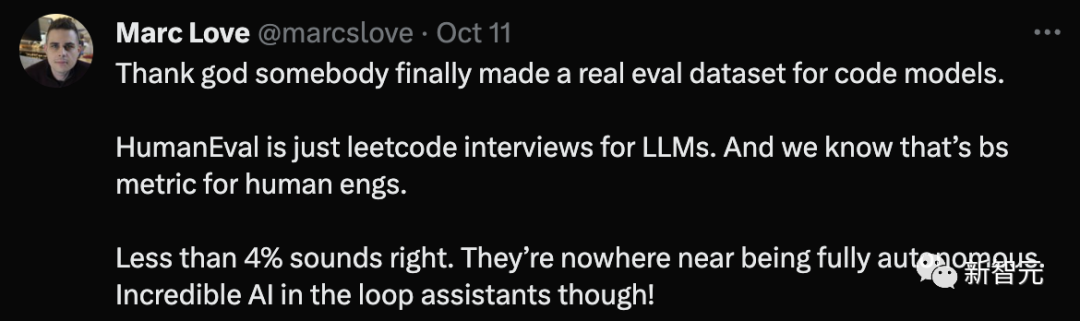
那么,SWE-bench评估大模型能力的结果,事实真是如此吗?
SWE-bench:专为编码模型设计
在这项研究中,作者发现,当前许多评测大模型编码能力的基准已经趋于饱和,无法评测出大模型真正的实力。
比如,HumanEval中,挑战问题太过简单,LLM只需要几行代码就能解决独立的问题。
然而,现实中软件工程并非如此简单。

修复一个bug可能需要浏览庞大的资源库,理解不同文件中函数之间的关系,又或者在错综复杂的代码中发现一个小错误。
受此启发,普林斯顿、芝大研究人员介绍了SWE-bench。
SWE-bench通过连接GitHub问题和解决相关测试的合并请求解决方案,从真实Python代码库中获取任务实例。
如图所示,模型的任务(通常是错误报告或功能请求)是解决提交到GitHub仓库的问题。
每项任务都需要生成一个补丁,并描述要应用到现有代码库中的更改。
然后使用仓库的测试框架SWE-bench,评估修改后的代码库。

为了找到高质量的大规模任务实例,研究者通过了三个阶段的筛选:

第一阶段:仓库选择和数据搜索。
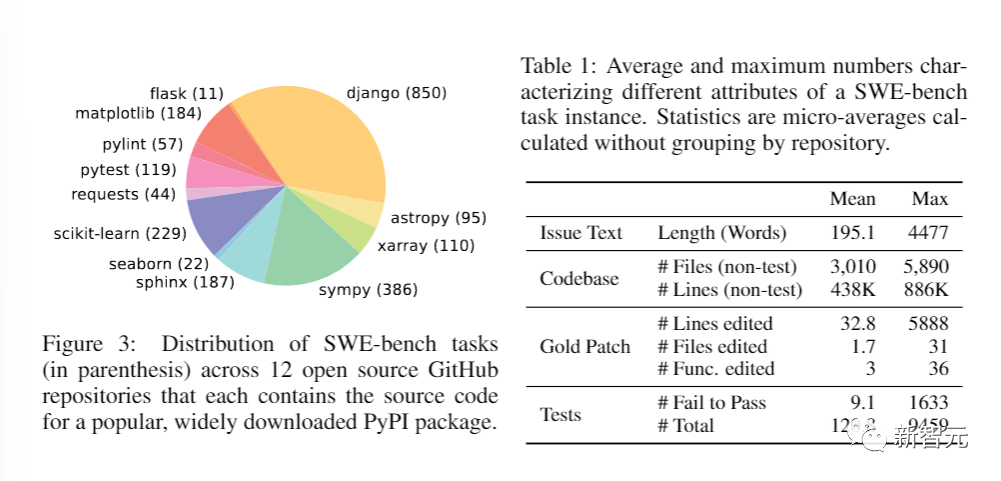
首先从GitHub上12个流行的开源Python代码库中收集拉取请求(PR),总共产生了约90,000个PR。
研究人员将重点放在流行的仓库上,因为这些仓库往往维护得更好,有明确的贡献者指南,并且有更好的测试覆盖率。每个PR都有一个相关的代码库,即PR合并前的仓库状态。
第二阶段:基于属性的筛选。
创建候选任务的方法是,选择符合以下条件的合并PR:(1)解决了GitHub问题;(2)修改了仓库的测试文件,这表明用户很可能贡献了测试来检查问题是否已解决。
第三阶段:基于执行的过滤。
对于每个候选任务,都会应用PR的测试内容,并记录应用PR其他内容前后的相关测试结果。
研究者会过滤掉没有至少一项测试的任务实例,这些测试的状态从失败变为通过(以下简称「失败到通过测试」)。此外,还会过滤掉导致安装或运行错误的实例。
通过这些阶段的筛选,原始的90,000个PR被筛选为2,294个任务实例,这些任务实例构成了SWE-bench。
如下图3所示,显示了这些任务实例在不同资源库中的最终分类,表是SWE-bench任务实例的主要特征。
研究者强调,这些代码库都很大,包含数千个文件,而且参考拉取请求通常会同时对多个文件进行修改。
与现有的LM编程基准相比,SWE-bench具有多项优势。
其中包括,利用用户提交的问题和解决方案的真实设置、来自12个资源库的独特代码问题为特色的多样化输入、基于执行的强大评估框架,以及利用新实例不断更新基准的能力,且只需极少的人工干预。
LLM任务:编辑代码库,解决问题
研究者会给大模型关于问题的文本描述,以及完整的代码库。
大模型的任务,就是对代码库进行编辑,来解决问题。
在实践中,研究者将修改表示为补丁文件,它会指定要修改代码库中的哪些行以解决问题。
如何评价LLM给出的方案好不好?
研究者会使用unix的补丁程序,将生成的补丁应用于代码库,然后执行与任务实例相关的单元和系统测试。
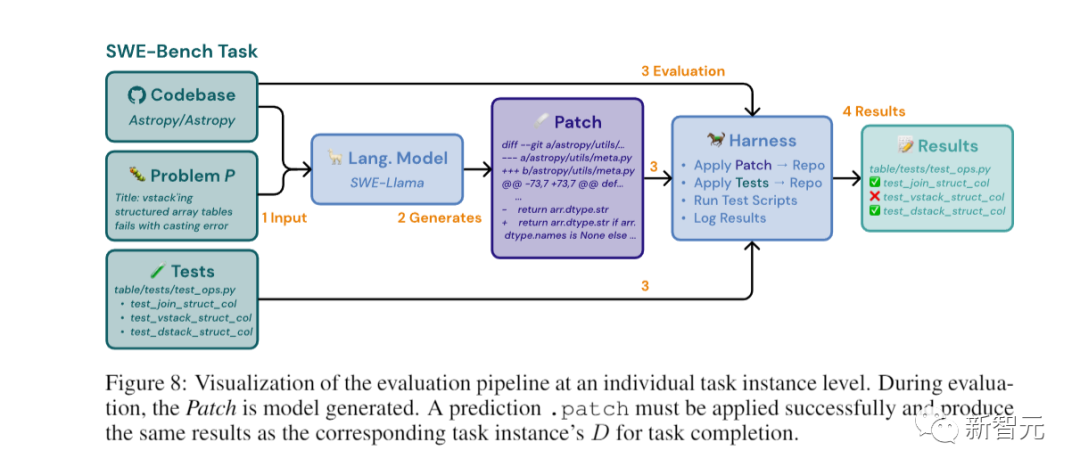
如果补丁应用成功,并且通过所有这些测试,就可以认为LLM建议的方案成功地解决了问题。
基准的度量指标,是已解析任务实例的百分比。
构建SWE-bench的独特数据集
传统的NLP基准,通常只涉及短的输入和输出序列,并考虑一些专门为基准创建的“人为”问题。
相比之下,为了构建SWE-bench,研究者为数据集注入了独特的属性。
比如,采用的是真实的软件工程任务。
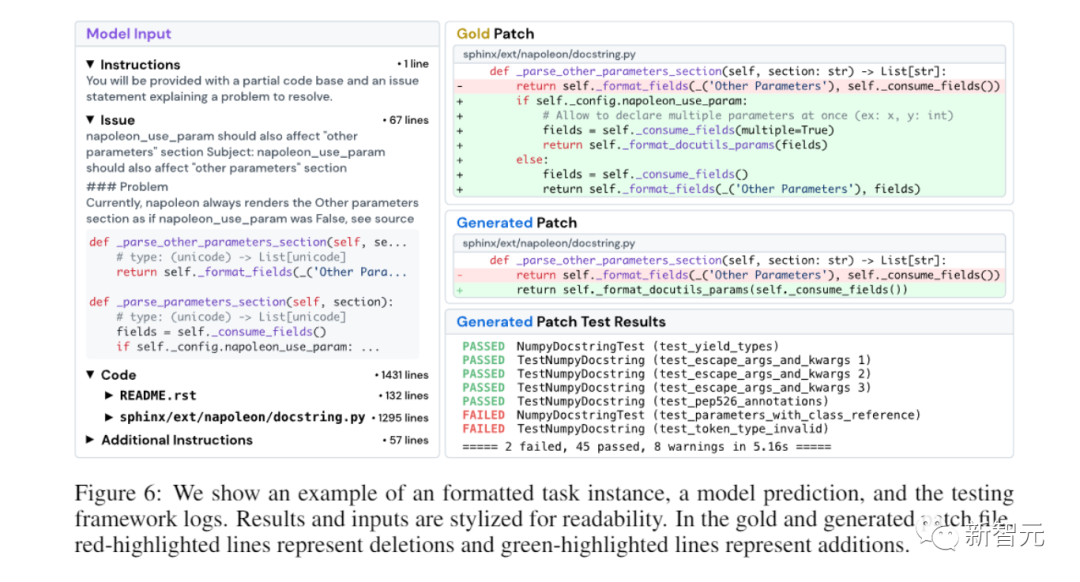
由于SWE-bench中的每个任务实例都包含一个庞大而复杂的代码库和相关问题的描述,解决SWE-bench,就需要经验丰富的软件工程师拥有的复杂技能和知识,但在传统的代码生成基准中,这些通常不被评估。
而且,收集过程可以轻松地应用于GitHub上的任何Python存储库,几乎不需要人工干预。
因此,研究者就可以通过不断提供新的任务实例来扩展SWE-bench,并就训练日期后创建的问题对语言模型进行评估,这就确保了训练语料库中,并没有包含解决方案。
此外,研究者还保证了基准中不同的长输入、稳健评估、跨上下文代码编辑、解决方案的广泛范围等。
微调SWE-Llama
接下来,就是到了评估开放模型与专有模型在SWE-bench框架的效果了。
可是研究者发现,现成的CodeLlama微调模型,无法遵循详细的指令生成整个资源库范围内的代码编辑,通常会输出占位符响应或不相关的代码。
为了评估这些模型的能力,研究人员对70 亿参数的CodeLlama-Python模型和130亿参数的CodeLlama-Python模型进行了监督微调(SFT)。
由此产生的模型是专门的仓库编辑器,可在消费级硬件上运行,并解决GitHub问题。

大模型都败北
接下来,研究者对GPT-3.5、GPT-4、Cluade 2以及微调的模型进行了评估。
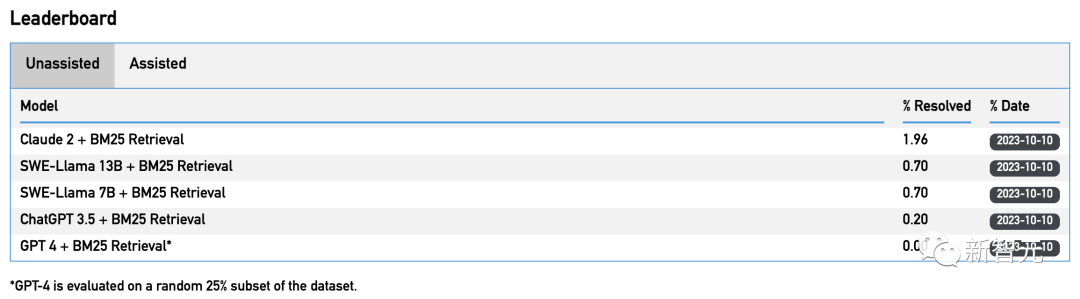
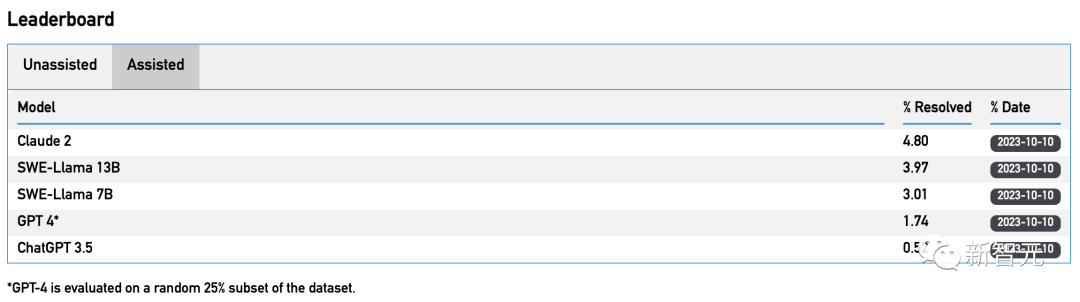
结果发现,所有模型都失败了——除了发现最简单的问题外,它们都无法解决所有问题。
比如,Claude 2和GPT-4分别只能解决4.8%和1.7%的任务。
在使用BM25检索器后,Claude 2的性能进一步下降到1.96%。
不同资源库的难度不同。
如果按资源库对性能进行细分,就会发现所有模型在不同资源库中都表现出相似的趋势。
尽管如此,每个模型所解决的问题并不一定广泛重叠。比如,在oracle设置中,Claude 2和SWE-Llama 13b的性能相当,每个模型分别解决了110个和91个实例。
难度与上下文长度相关。
模型可以在长代码序列上进行预训练,但通常要求一次生成单个函数,并提供有限的上下文来确定问题的框架。
如图所示,可以看到随着上下文总长度的增加,Claude 2 的性能大幅下降,这种情况在其他模型中也可以观察到。
即使增加BM25的最大上下文大小,会提高相对于甲骨文文件的召回率,但性能仍然会下降,因为模型根本无法在茫茫词库中定位有问题的代码。
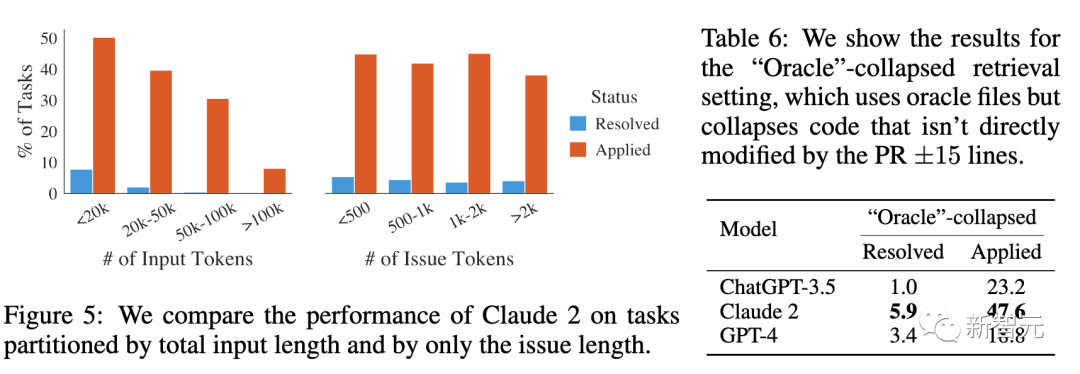
难度与问题解决日期无关。
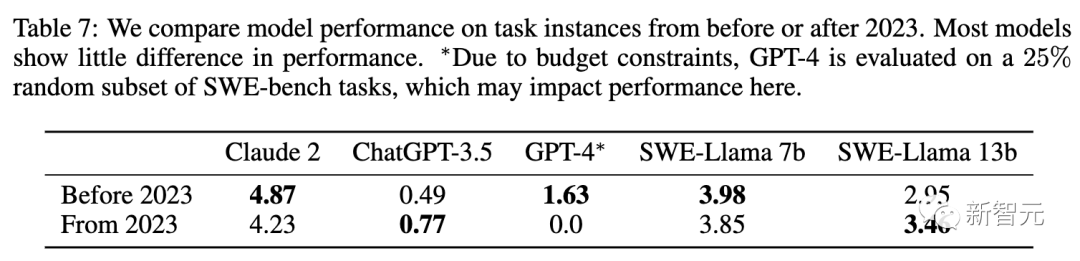
在表7中,展示了在「oracle」检索设置下,针对2023年之前或之后创建的 PR,按日期划分的模型结果。
对于大多数模型来说,除GPT-4外,在这一日期之前或之后的性能差别不大。
另外,研究还发现微调模型对上下文分布变化很敏感,生成补丁比生成整个文件更容易。而且大模型倾向于生成更短、更简单的编辑。
LLM无法替代程序员,但可以加快工作流
有网友对「通才模型」的未来有所憧憬和希望。
没错,这也是我的经验之谈。通才模型还不够好,没有足够宽的上下文长度,除了相对较短的代码片段外,无法自行编码。
但我认为这只是时间问题。我可以预见,在不久的将来,接受过特定训练的通才LLM将成为非常专业的模型。
虽然大模型无法替代程序员,但可以加速他们的工作流。过去需要10人的团队,现在可能只需要4个人。这样就能腾出资源,用于公司筹备的其他目标。
与其为了省钱而解雇员工,不如让开发人员惊人的速度完成伟大的事业!

参考资料:
https://www.reddit.com/r/MachineLearning/comments/1795iiz/can_ai_replace_developers_princeton_and/
https://twitter.com/_carlosejimenez/status/1711714120175681552
https://www.swebench.com/
https://futurism.com/the-byte/stack-overflow-layoffs-ai
https://arstechnica.com/gadgets/2023/10/after-chatgpt-disruption-stack-overflow-lays-off-28-percent-of-staff/?comments=1&comments-page=1
,普林斯顿芝大惊人发现:GPT-四川招生考试网 4解决GitHub编程问题成功率为0相关:
特朗普:如再当选,将禁止支持哈马斯的移民进入美国【环球网报道 见习记者 赵博元】据路透社报道,美国前总统特朗普周一(16日)表示,如果他再次当选总统,将禁止支持哈马斯的移民进入美国,并将对公开支持“巴勒斯坦激进组织”的移民进行逮捕和驱逐。报道称,特朗普是在艾奥瓦州一次竞选活动中对新一轮巴以冲突做出了相关表态。路透社称,特朗普上周指责以色列总理内塔尼亚胡对哈马斯的袭击毫无准备,称伊朗支持的黎巴嫩真主党“非常聪明”。他此次在艾奥瓦州的最新发言似乎在..
巴以冲突加剧,中国驻美大使馆提醒!近日,巴以冲突局势加剧,美国部分大学校园里爆发示威游行,个别校园内甚至发生暴力冲突,且这种冲突有蔓延到美国各地高校校园的可能,我在美留学人员人身安全面临较大风险。驻美使馆提醒在美留学人员注意校园抗议示威活动和当地安全形势,增强风险防范意识,加强自我保护,避免前往示威游行活动涉及的公众场所和人员密集地,确保人身、财产和出行安全。如遇危险或突发情况,请及时报警并与中国驻美使领馆联系。全美报警、求助电..
德媒分析:以军地面进攻为何依赖天气参考消息网10月17日报道 据德国《世界报》网站10月15日报道,天气预报显示,15日白天“晴,最高气温25摄氏度”,但晚间多云,夜间甚至还会有雷阵雨。这对地面进攻来说并非理想条件,尤其是16日预计仍将是坏天气。报道指出,军队急需的侦察无人机和战斗机的能见度都受到影响。以色列军方很可能出于这个原因,暂时推迟了对加沙地带的巴勒斯坦伊斯兰抵抗运动(哈马斯)的“铁剑”行动。以色列军方已调动30万士兵包围了整个加沙地带..
辽上京考古发现一处东向院落遗址 记者从中国社会科学院考古研究所和内蒙古文物考古研究院联合组成的辽上京考古队获悉,辽上京皇城遗址2023年考古发掘又有新发现。近日,考古队在辽上京皇城遗址发现一处布局清楚、体量很大的东向院落,这对认识辽上京皇城布局、进一步探索辽上京皇家礼制建筑提供了十分重要的线索。 据介绍,该东向院落为一处平面呈长方形、四面带回廊的大型院落。它的东侧有一个门址,沿着轴线从东至西,建有前殿和后殿。两座大型殿址..
业主私挖地下室竟挖通河道?律师:或面临刑事处罚 中新网北京10月17日电(韦香惠)私挖地下室竟然挖通河道?近日, 江苏南京建邺区江心洲亚鹏路一小区,因业主私挖院落土方并破坏地下室外墙,导致河水倒灌地下车库,引发社会关注。目前,当地有关部门已介入调查。律师表示,不仅业主要承担责任,房产建设方,设计方,施工方等都有可能被追责。 视频截图: 涉事小区车库进水情况 小区业主私挖地下室竟挖通河道 公安部门已立案,多部门联合调查 近日,江苏..
学校中介联手挖坑,职校生就业陷阱知多少? 职校生就业乱象应予重视 中国新闻周刊记者/周群峰 发于2023.10.16总第1112期《中国新闻周刊》杂志 湖南省常德海乘职业学校与深圳一家劳务中介合作,将多名毕业生介绍到菲律宾从事“客服、文员”工作。这些毕业生去后才发现,他们从事的工作其实是联系一些赌客(主要来自中国境内)在赌博平台下赌注。回国后,他们因涉嫌开设赌场罪相继被捕。 多名毕业生受访时并未否认自己从事的工作触犯了法律。尽管如此..
华西会诊医生谈被狗咬伤女童病情:身上有20多处撕咬伤从下午5点过,医院通知要院外会诊,和儿外的曾莉,胸外的刘成武一起,搭乘救护车一路在拥堵的成都晚高峰上飞奔。导航显示59分钟,实际花了25分钟。一路上,看了大狗撕咬小娃娃的视频,触目惊心,心情也有些忐忑。进入小儿ICU,换隔离衣,听取病情汇报,看检查检验结果,分析病情,制定初步治疗方案。目前,最大的危险,来自腹膜后右肾损伤及它所形成的血肿,目前经过讨论,我们一致认为,如果现在探查,丢肾的概率非常高,所以对..
加沙医院院长拒绝以军撤离要求:我们不能看着他们死去10月9日,加沙,医护人员照料一名在空袭中受伤的儿童。海外网10月17日电 据美国有线电视新闻网10月17日报道,巴勒斯坦加沙地带拉法市的科威特医院16日表示,他们已经第2次收到以色列军方发出的撤离警告,但是医院院长拒绝离开。医院院长苏海卜·哈姆斯表示,他不会撤离,因为为伤者服务、帮助有需要的人是医务人员的职责,他们不能看着病人死去。他表示,医院应该受到国际法的保护。14日晚,世界卫生组织曾发表声明,强烈谴责以..
白宫宣称美国向以色列提供军事援助“不设任何条件”【环球网报道 见习记者 赵博元】巴以新一轮大规模冲突持续不断,已造成双方逾4200人死亡,2万多人受伤。据《以色列时报》17日报道,美国白宫国家安全委员会战略沟通协调员约翰·柯比称,美国不会对向以色列提供军事援助“设任何条件”。美国白宫国家安全委员会战略沟通协调员约翰·柯比 资料图 图源:外媒报道称,约翰·柯比在一次电话通报会上对记者说,“他们有权自卫。他们有权追查这一恐怖威胁,我们将继续尽一切努力帮..
哈马斯没想到,自己有这么多粉丝这一轮哈马斯-以色列的冲突发展到今天,事情已经越来越清晰。由于冲突的导火索是哈马斯发起对以色列境内平民的无差别屠杀和绑架,引发以色列强烈反弹,而后以色列发布警告敦促即将被袭击的北部加沙地区居民撤离,哈马斯阻挠撤离,以至于24小时之后以色列再次延长撤离期限。10月16日巴勒斯坦总统阿巴斯谴责双方行为,并表示哈马斯不代表巴勒斯坦人民。简而言之,支持巴勒斯坦并不代表支持哈马斯,因为哈马斯并非巴勒斯坦政府代表..