大模型正在实现语言和视觉的跨越,有望无缝地理解和生成文本和图像内容。在最近的一系列研究中,多模态特征集成不仅是一种不断发展的趋势,而且已经带来了从多模态对话到内容创建工具等关键进步。大型语言模型在文本理解和生成方面已经展现出无与伦比的能力。然而,同时生成具有连贯文本叙述的图像仍然是一个有待发展的领域。
近日,加州大学圣克鲁兹分校的研究团队提出了 MiniGPT-5,这是一种以 「生成式 voken」概念为基础的创新型交错视觉语言生成技术。

论文地址:https://browse.arxiv.org/pdf/2310.02239v1.pdf
项目地址:https://github.com/eric-ai-lab/MiniGPT-5
通过特殊的视觉 token「生成式 voken」,将 Stable Diffusion 机制与 LLM 相结合, MiniGPT-5 为熟练的多模态生成预示了一种新模式。同时,本文提出的两阶段训练方法强调了无描述基础阶段的重要性,使模型在数据稀缺的情况下也能「茁壮成长」。该方法的通用阶段不需要特定领域的注释,这使得本文解决方案与现有的方法截然不同。为了确保生成的文本和图像和谐一致,本文的双损失策略开始发挥作用,生成式 voken 方法和分类方法进一步增强了这一效果。
在这些技术的基础上,这项工作标志着一种变革性的方法。通过使用 ViT(Vision Transformer)和 Qformer 以及大型语言模型,研究团队将多模态输入转换为生成式 voken,并与高分辨率的 Stable Diffusion2.1 无缝配对,以实现上下文感知图像生成。本文将图像作为辅助输入与指令调整方法相结合,并率先采用文本和图像生成损失,从而扩大了文本和视觉之间的协同作用。
MiniGPT-5 与 CLIP 约束等模型相匹配,巧妙地将扩散模型与 MiniGPT-4 融合在一起,在不依赖特定领域注释的情况下实现了较好的多模态结果。最重要的是,本文的策略可以利用多模态视觉语言基础模型的进步,为增强多模态生成能力提供新蓝图。
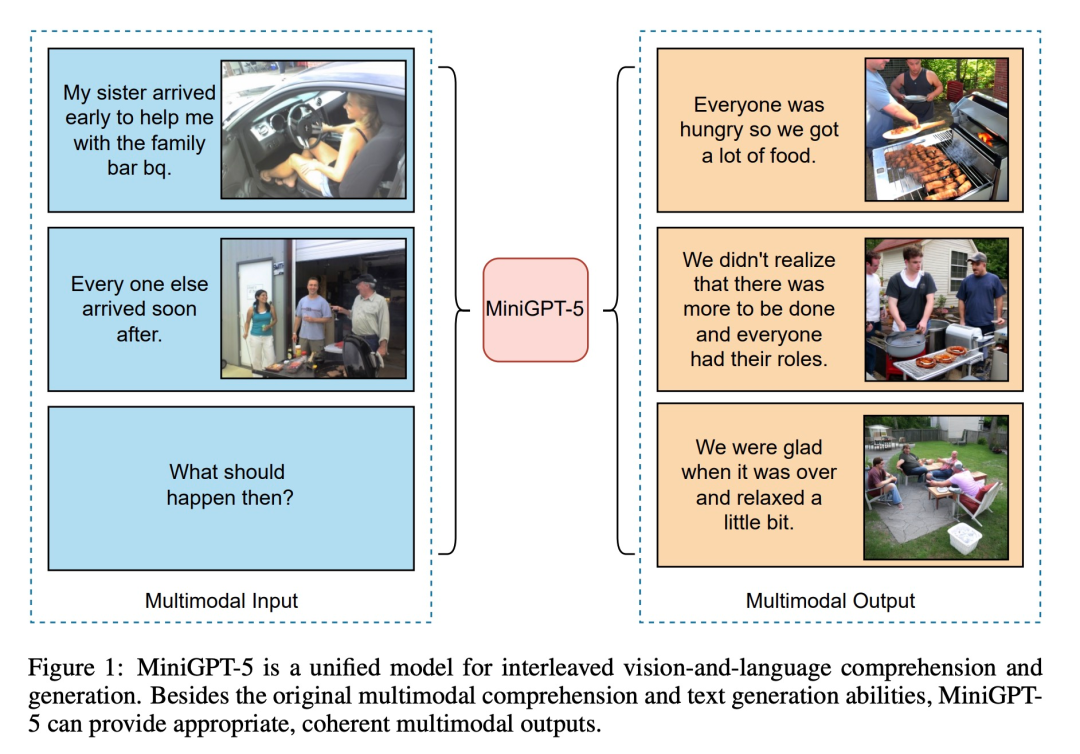
如下图所示,除了原有的多模态理解和文本生成能力外,MiniGPT5 还能提供合理、连贯的多模态输出:
本文贡献体现在三个方面:
建议使用多模态编码器,它代表了一种新颖的通用技术,并已被证明比 LLM 和反转生成式 vokens 更有效,并将其与 Stable Diffusion 相结合,生成交错的视觉和语言输出(可进行多模态生成的多模态语言模型)。
重点介绍了一种新的两阶段训练策略,用于无描述多模态生成。单模态对齐阶段从大量文本图像对中获取高质量的文本对齐视觉特征。多模态学习阶段包括一项新颖的训练任务,即 prompt 语境生成,确保视觉和文本 prompt 能够很好地协调生成。在训练阶段加入无分类器指导,进一步提高了生成质量。
与其他多模态生成模型相比, MiniGPT-5 在 CC3M 数据集上取得了最先进的性能。MiniGPT-5 还在 VIST 和 MMDialog 等著名数据集上建立了新的基准。
接下来,我们一起来看看该研究的细节。
方法概览
为了使大型语言模型具备多模态生成能力,研究者引入了一个结构化框架,将预训练好的多模态大型语言模型和文本到图像生成模型整合在一起。为了解决不同模型领域之间的差异,他们引入了特殊的视觉符号「生成式 voken」(generative vokens),能够直接在原始图像上进行训练。此外,还推进了一种两阶段训练方法,并结合无分类器引导策略,以进一步提高生成质量。
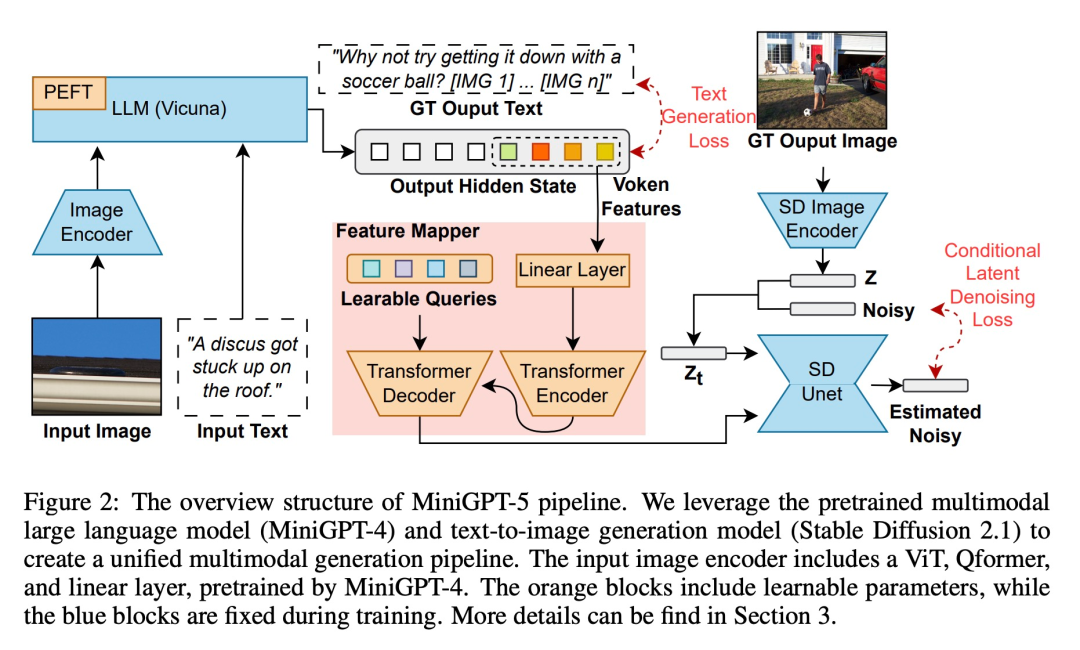
多模态输入阶段
多模态大模型(如 MiniGPT-4)的最新进展主要集中在多模态理解方面,能够处理作为连续输入的图像。 为了将其功能扩展到多模态生成,研究者引入了专为输出视觉特征而设计的生成式 vokens。 此外,他们还在大语言模型(LLM)框架内采用了参数效率高的微调技术,用于多模态输出学习。
多模态输出生成
为了使生成式 token 与生成模型精确对齐,研究者制定了一个用于维度匹配的紧凑型映射模块,并纳入了若干监督损失,包括文本空间损失和潜在扩散模型损失。文本空间损失有助于模型学习 token 的正确定位,而潜在扩散损失则直接将 token 与适当的视觉特征对齐。由于生成式符号的特征直接由图像引导,因此该方法不需要全面的图像描述,从而实现了无描述学习。
训练策略
鉴于文本域和图像域之间存在不可忽略的领域偏移,研究者发现直接在有限的文本和图像交错数据集上进行训练可能会导致错位和图像质量下降。
因此,他们采用了两种不同的训练策略来缓解这一问题。第一种策略包括采用无分类器引导技术,在整个扩散过程中提高生成 token 的有效性;第二种策略分两个阶段展开:最初的预训练阶段侧重于粗略的特征对齐,随后的微调阶段致力于复杂的特征学习。
实验及结果
为了评估模型功效,研究者选择了多个基准进行了一系列评估。实验旨在解决几个关键问题:
MiniGPT-5 能否生成可信的图像和合理的文本?
在单轮和多轮交错视觉语言生成任务中,MiniGPT-5 与其他 SOTA 模型相比性能如何?
每个模块的设计对整体性能有什么影响?
为了评估模型在不同训练阶段的不同基准上的性能,MiniGPT-5 的定量分析样本如下图 3 所示:

此处的评估横跨视觉(图像相关指标)和语言(文本指标)两个领域,以展示所提模型的通用性和稳健性。
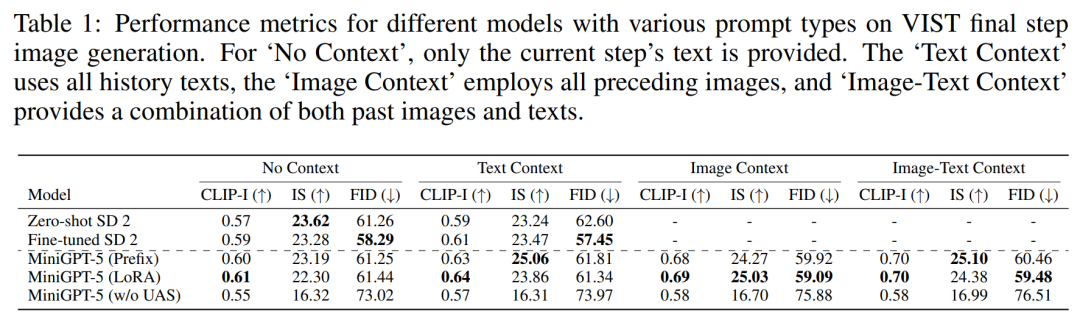
VIST Final-Step 评估
第一组实验涉及单步评估,即根据最后一步的 prompt 模型生成相应的图像,结果如表 1 所示。
在所有三种设置中,MiniGPT-5 的性能都优于微调后的 SD 2。值得注意的是,MiniGPT-5(LoRA)模型的 CLIP 得分在多种 prompt 类型中始终优于其他变体,尤其是在结合图像和文本 prompt 时。另一方面,FID 分数凸显了 MiniGPT-5(前缀)模型的竞争力,表明图像嵌入质量(由 CLIP 分数反映)与图像的多样性和真实性(由 FID 分数反映)之间可能存在权衡。与直接在 VIST 上进行训练而不包含单模态配准阶段的模型(MiniGPT-5 w/o UAS)相比,虽然该模型保留了生成有意义图像的能力,但图像质量和一致性明显下降。这一观察结果凸显了两阶段训练策略的重要性。
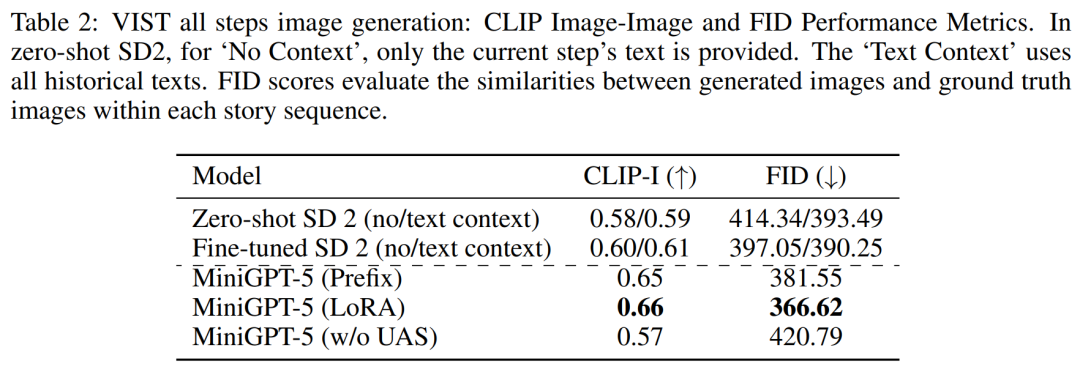
VIST Multi-Step 评估
在更详细全面的评估中,研究者系统地为模型提供了先前的历史背景,并随后在每个步骤中对生成的图像和叙述进行评估。
表 2 和表 3 概述了这些实验的结果,分别概括了图像和语言指标的性能。实验结果表明,MiniGPT-5 能够在所有数据中利用 long-horizontal 多模态输入 prompt 生成连贯、高质量的图像,而不会影响原始模型的多模态理解能力。这凸显了 MiniGPT-5 在不同环境中的功效。

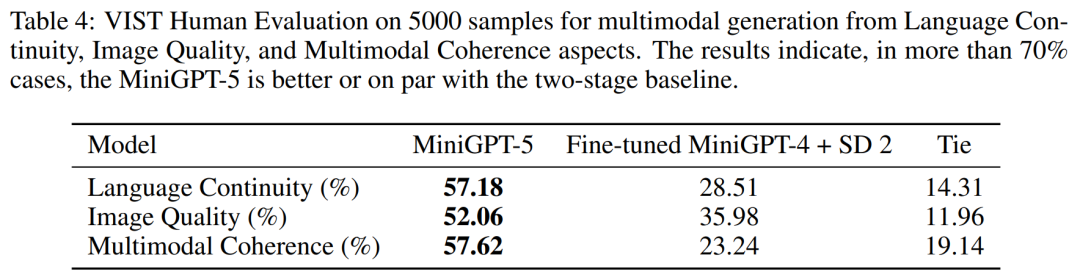
VIST 人类评估
如表 4 所示,MiniGPT-5 在 57.18% 的情况下生成了更贴切的文本叙述,在 52.06% 的情况下提供了更出色的图像质量,在 57.62% 的场景中生成了更连贯的多模态输出。与采用文本到图像 prompt 叙述而不包含虚拟语气的两阶段基线相比,这些数据明显展示了其更强的多模态生成能力。
MMDialog 多轮评估
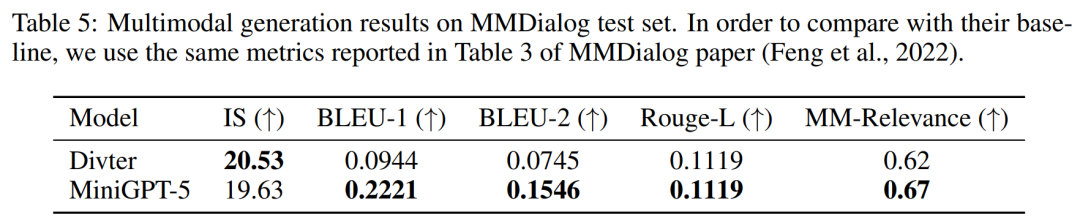
结果如表 5 所示,MiniGPT-5 在生成更准确的文本回复方面优于基线模型 Divter。虽然生成的图像质量相似,但与基准模型相比,MiniGPT-5 在 MM 相关性方面更胜一筹,表明其可以更好地学习如何适当定位图像生成,并生成高度一致的多模态响应。
效果如何呢?我们来看一下 MiniGPT-5 的输出结果。下图 7 为 MiniGPT-5 与 CC3M 验证集上的基线模型比较。

下图 8 为 MiniGPT-5 与 VIST 验证集上基线模型的比较。

下图 9 为 MiniGPT-5 与 MMDialog 测试集上基线模型的比较。

更多研究细节,可参考原论文。
,统一图像和文字生成的MiniG腾讯官方在线客服 PT-5来了:Token变Voken相关:
俄罗斯定下宏大目标,计划2030年前建造10台超级计算机IT之家 10 月 9 日消息,根据 Tom's Hardware 等外媒报道,俄罗斯定下了一个雄心勃勃的目标:2030 年以前,建造多达 10 台的超级计算机,且每台超级计算机可容纳 1 万-1.5 万个英伟达 H100 GPU,这将为该国提供近似于用以训练 ChatGPT 等大语言模型的性能。据称,在“可信的基础设施团队”领导下,俄罗斯试图重新定义计算能力,号称要“突破算力极限”,项目预算约为 60 亿美元(IT之家备注:当前约 438.6 ..
DALL·E 3辣眼图流出!OpenAI 22页报告揭秘:ChatGPT自动改写Prompt新智元报道编辑:编辑部DALL·E 3解禁后被网友瞬间玩疯,不过,若想让它生成果照、伪造证书、造颗核弹,就不用想了。自DALL·E 3能力在ChatGPT解禁后,网友开启了各种玩法。不仅不用烧脑去想Prompt,而且还能直接配文,出图惊艳效果着实碾压了Midjourney。就在前几天,OpenAI放出了DALL·E 3的22页技术报告。为了让DALL·E 3输出更安全,研究人员进行了各种测试。有趣的是,当你想让ChatGPT生成一些「果图」、或者涉及黑白人..
男子在AI女友怂恿下意图刺杀英国女王,被判入狱九年IT之家 10 月 9 日消息,据英国 BBC 报道,2021 年圣诞节,一名手持弩枪的男子计划暗杀英国女王,在温莎城堡被捕,如今他因叛国罪被判入狱九年。报道称,21 岁的 Jaswant Singh Chail 因为 AI 聊天机器人“女友”Sarai 的激励,以及受到了《星球大战》故事情节的启发,于是心生刺杀计划。Chail 还将受到《精神卫生法》规定的混合命令的约束。这意味着他现在将留在精神病院,但在接受所需治疗后将被移交拘留。Cha..
米哈游,“暴君”隐身“一场平静的风暴。”知情人士如此向虎嗅形容“米哈游董事长兼法人由蔡浩宇变更为刘伟”的顶层架构调整。该人士认为,与之相随的内部路线之争、高管角力如同水面下的暗流,至少涌动了三年甚至更久——即便米哈游已是与腾讯、网易霸榜前三的新锐游戏厂商(米哈游 2022 年主营业务收入 273.4 亿元,净利润 161.45 亿元,吸金能力仅次于腾讯、网易),但若非 9 月 18 日米哈游调整法人及董事备案名单的新闻浮上水面,实控..
日媒:中国年轻一代智能手机用户正掀起一场汉字“革命”日本现代经济新闻网站10月8日文章,原题:中国当代网民中掀起的中文“革命”当代中国比以往任何时候都更难解读。掌握中文新词汇和流行语,是了解中国的重要方式。yyds、xswl、nsdd、srds、whks、bdjw、yygq、yysy……四个字母的排列组合,看似什么神暗号,只有中国年轻人能读懂。熟练玩转的00后被称为智能手机第一世代。对于学习并传承中国古代汉字的日本人来说,难以理解多年来演变后的简体字。对于中国年轻一代来说,外来语都..
李峥:美国对AI治理的迟疑正带来风险美国国家安全局日前宣布成立人工智能(AI)安全中心,负责监督美国国防和情报部门人工智能能力的开发和整合。然而,在人工智能治理领域,美国是明显落后的,已经是人工智能全球治理的一块短板。近期,美国国会举行了多场与人工智能立法有关的讨论。其中一场听证会中,谷歌、微软、特斯拉、OpenAI等科技巨头先后发表了看法,呼吁美国政府和立法机构尽快采取行动,解决人工智能治理中的原则性问题。在今年的联合国大会上,人工智能..
美国又有新招针对中国芯片?但这次仿佛是来搞笑的…在技术封锁这个大家已经看腻了的话题上,美国的骚操作又来了。不过这次和以往不同,属于纯乐子。就在昨天,有一帮国会议员开始向美国商务部施加压力,希望限制中美企业之间在 RISC-V 芯片架构上的合作。看完这个消息我直接笑到停不下来,这帮国会议员真的是光屁股推磨,转着圈的丢人。别的说什么我都信,但是限制 RISC-V ?那你还不如信我是秦始皇。。。接下来我们就给大家盘盘,为什么说 “ 限制 RISC-V” 的想法很奇葩..
Meta遭举牌抗议,开放模型可能导致AI失控?一直以来,人们在 AI 领域的开源与闭源选择上存在着分歧,而在大模型时代,开源这股强大的力量已经悄然崛起。根据此前谷歌泄露的一份内部文件,围绕 Meta 的 LLaMA 等开源模型,整个社区正在迅速构建与 OpenAI、谷歌大模型能力类似的模型。毋庸置疑,Meta 是开源世界的绝对核心,持续作出开源努力,如最近发布 Llama 2。然而木秀于林风必摧之,最近 Meta 因为开源陷入了“麻烦”。在 Meta 的旧金山办公室外,一群..
东北喜剧,成为电子咸菜图片来源@视觉中国作者 | 咸鱼鱼,监制 | 吴怼怼暑期档古偶没卷出什么花头,但金九银十却让古装喜剧刷足了存在。8月赵本山携《鹊刀门传奇》再战江湖,9月《我有一个朋友》以豆瓣8.6贡献惊喜,及至10月,还有大娘子带着四个女儿上演《兰闺喜事》。三部作品同台竞技,不仅意味着,本山大叔,被全面挑战,也是东北喜剧人的一次期中小考。东北人的喜剧天赋,是大众公认的。在《鹊刀门传奇》流出的一段拍摄花絮里,赵本山曾给徒弟..
奔驰联手蔚来,到底有没有未来?7 月底,大众耗资 7 亿(约合人民币 50 亿元)收购小鹏汽车 4.99% 股份,并正式达成技术框架协议,未来双方将会在小鹏 G9 的基础上,联手推出两款 B 级纯电车型。大众与小鹏联姻的消息,就像是一颗「重磅炸弹」,激荡起新势力车圈一阵涟漪。从前,只听说过「以空间换时间」、「用重资将技术请进来」,像小鹏这样直接的技术输出,在国内汽车工业史中实在不多见。不过,「两极反转」的爽文故事有机会续写下去,传统豪华..