近日,AI 创业公司 Cohere 更进一步,将混合专家方法与 PEFT 组合,实现了极其参数高效的微调 —— 即使是在未曾见过的任务上,这种新方法只需更新不到 1% 的参数,就能实现与完全微调方法相当的性能。
Cohere 公司在攻克这些挑战上迈出了重要一步,提出了一个新框架 —— 可在大幅受限的计算环境中利用 MoE 的优势。

论文链接:https://arxiv.org/abs/2309.05444
代码链接:https://github.com/for-ai/parameter-efficient-moe
传统的训练范式是将模型的权重应用于每个输入。有理由相信这种方法效率不高,因为单个输入可能无法让模型发挥全部力量。
相比之下,混合专家(MoE/Mixture of Experts)则是基于多个子模块组件(即所谓的专家),这些组件可以专门处理不同类型的输入。这种对于条件计算的强调对效率具有重要的影响,比如会有恒定的推理成本。这使得 MoE 成了大规模 Transformer 时代一个重要的研究领域并得到了广泛的采用;而在这些应用中,规模的扩张也会造成部署成本和延迟上升。
尽管截至目前的大部分研究关注的是将 MoE 用作一种预训练策略,但 MoE 的内在动机并不仅局限于预训练。事实上,MoE 具有一些非常适合指令微调的特性;在指令微调设置中,数据会被刻意地构建,以代表多样化的任务,这通常也被称为多任务微调。
基于这一观察,AI 创业公司 Cohere 提出了一个问题:能否使用 MoE 来进行指令微调?MoE 范式的一大主要缺点是会引入大量参数。尽管是基于条件执行计算,但完全微调 MoE 架构需要更新所有参数,这需要非常大量的计算。对于大多数实践者来说,考虑到现代 LLM 的规模,这样的计算成本是无力支撑的。
于是,Cohere 公司关注的是更为现实的实践场景,即将 MoE 用于参数高效型微调(PEFT)方法,如 (IA)³ 或 LORA,它们微调的参数数量会少很多。这是一个重大挑战,不仅因为目标是仅更新所有参数的一小部分,而且因为还要在更受限的环境中解决 MoE 固有的优化挑战。
他们引入了 Mixture of Vectors(MoV)和 Mixture of LORA(MoLORA),一种参数高效型混合专家适应方法。不同于标准的 MoE,这种新框架很轻量,可用于对参数有限制的场景。
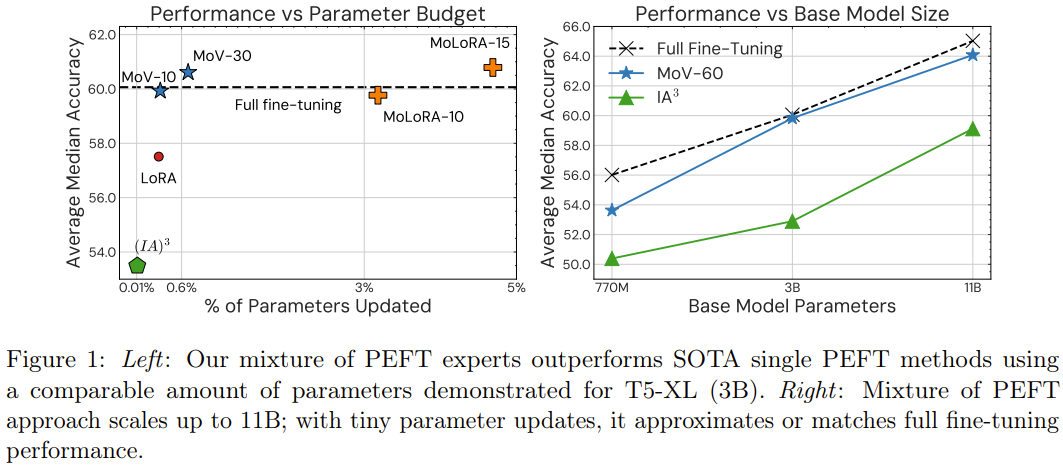
值得注意的是,在未曾见过的任务上,这种新方法只需更新不到 1% 的参数,就能实现与完全微调方法相当的性能。其表现也能轻松胜过 (IA)³ 或 LORA 等基础的参数高效型技术。
该团队基于 55 个数据集,在 12 个不同任务上,用 770M 到 11B 的不同大小 T5 模型进行了实验,得到了相当一致的结果。
本文的主要贡献包括:
1. 提出了极其参数高效的 MoE。该架构利用了模块化和轻量级的专家,可在更加现实的设置中使用 MoE。使用这个新提出的 MoE 来训练一个密集模型时,仅需更新其不到 1% 的参数。
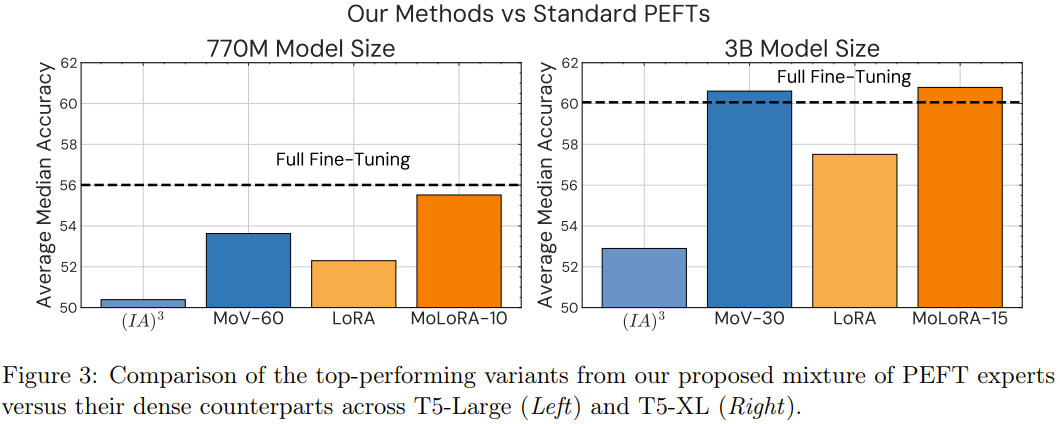
2. 使用新提出的方法执行指令微调时,在未曾见过的任务上能取得持续优于传统参数高效方法的性能,同时还能为不同大小的模型维持较高的参数效率。相较于 3B 和 11B 模型大小的标准 (IA)³,混合 (IA)³ 向量(MoV)分别实现了 14.57% 和 8.39% 的提升。这种优越性在各种大小的模型、各种类型的专家和可训练参数负载上都有体现。
3. 研究表明新提出的方法能取得与大规模完全微调方法相当的性能表现,同时只需更新一小部分模型参数。研究者在 8 个未曾见过的任务上进行了实验,结果表明 MoV 仅会分别更新 3B 和 11B 模型中 0.32% 和 0.86% 的参数,却能以显著更低的计算成本实现与完全微调方法相当的表现。
4. 他们也进行了一系列广泛的消融研究,系统性地评估了各种 MoE 架构和 PEFT 策略的效能,涉及多种模型大小、不同的适应器类型、专家的数量、路由机制和优化超参数的重要性,尤其是考虑到 MoE 的敏感性。
方法
指令微调可以形式化地表述为:存在一个任务集合 T,将其分为训练任务集 T_train 和留存评估集 T_eval。
首先在 T_train 上对基础预训练模型进行微调,然后使用零样本方式在 T_eval 中的每个任务上评估微调后的模型。标准的微调方法是微调所有模型参数,这样会有很高的计算和内存成本。新提出的方法却有很高的参数效率,其使用了参数高效型混合专家,下面详细描述一下该框架。
(IA)³ 和 LORA 参数高效型微调方法
参数高效型微调(PEFT)方法只会更新少量参数的权重。为了展示新方法适用于不同的 PEFT 技术,研究者实验了 (IA)³ 和 LORA。这些方法会向已有的预训练模型模型添加少量参数。这里就不对 (IA)³ 和 LORA 做更详细的介绍了,感兴趣的读者可参阅原论文以及机器之心的报道《调教 LLaMA 类模型没那么难,LoRA 将模型微调缩减到几小时》。
极其参数高效的混合专家
新提出的极其参数高效的 MoE 框架使用了轻量级的「适应器」作为预训练密集模型之上的专家。
具体来说,MoE 是一系列神经网络架构,可以通过基于门控机制(路由器)激活的多个专家来进行条件计算。MoE 层由一个路由器网络 R 和一个专家集合 E 构成,其中 E 包含 n 个专家,每个专家 E_i 都是一个已参数化的函数。至于路由器网络 R 的设计,该团队参照了论文《Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity》,通常由一个密集层后带一个 softmax 函数构成;其中这个密集层有可训练的权重 W_g,softmax 函数则是以中间 token 表征 x 为输入并基于门控分数 s_1, ..., s_n 将每个专家的输出组合到一起:
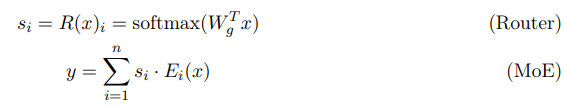
对于 Transformer 模型,其中的密集型前向层被 MoE 层取代,该层中每个专家 E_i 都对应于一个独立的密集型前向网络。随着每个专家的规模和专家数量的增加,模型的参数总数会成倍增大。但是,在新提出的参数高效型 MoE 架构中,每一个专家都被一个轻量级 PEFT 适应器(比如 (IA)³ 向量或 LORA 适应器)替代。
在微调过程中,密集层的预训练权重保持固定,而专家层和路由器层则从头开始训练。不同于标准 MoE,这种新提出的轻量级专家可以在微调时间学习适应预训练 Transformer 层。这样一来,新的 MoE 框架只需要少量参数更新,而不是整体对大模型进行更新。
除了参数效率之外,研究者选择的 PEFT 适应器可通过 soft merging 实现路由计算。具体来说,由于 (IA)³ 向量和 LORA 适应器都是线性函数,所以他们首先会计算专家的加权平均,然后使用组合后的专家 E_mix 应用一个 PEFT 变换:
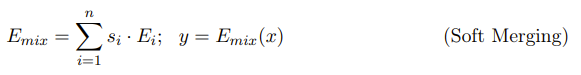
对于把 (IA)³ 向量或 LORA 适应器分别用作专家的方法,研究者将它们分别命名为 Mixture of Vectors (MoV) 和 Mixture of LORA (MoLORA),这两种方法都能持续稳定地优于对应的 PEFT 方法。下图 2 展示了 MoV 层的架构以及相应的伪代码。
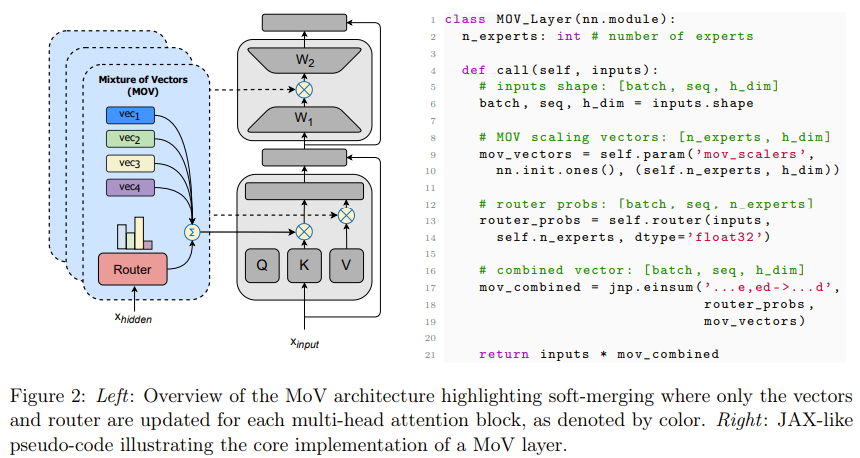
通过 MoV 和 MoLORA 只更新少部分参数有一些实际的好处 —— 不仅有益于训练,也有助于推理;对于后者的优势是 MoE 架构所独有的。下面简要描述一些这些好处:
训练效率
这种极其参数高效的 MoE 形式可以显著减少内存消耗。通过在训练期间冻结大多数参数,不仅能减少计算模型参数的梯度的计算开销,而且还可降低存储模型的优化器状态的内存需求。根据优化器的选择,后者可能非常重要,举个例子,AdamW 等 Adam 优化器变体为了存储优化器状态,每个参数需要两倍的内存(根据一阶矩和二阶矩的估计),而 Adafactor 则能通过分解二阶参数矩的估计来将这种开销减半。
推理效率
MoV 和 MoLORA 方法的固有结构模块化特性能为推理带来显著的内存效益。对于传统的 MoE 模型,很多完全用于前向的块的副本(甚至基于特定架构的模型的完整副本)需要在推理时间被存储在内存中,这种做法的成本很高。
使用这种方法,不管确切的类型如何,都只需要将模型主干的一个副本保存在内存中,外加上轻量级参数高效型专家。这能在推理时间显著降低对内存的需求。
实验
参数高效型 MoE 与 PEFT 方法:新的 MoE 方法与单专家型 PEFT 方法相比如何?下表 1 比较了 PEFT 方法((IA)³ 和 LORA)与新提出的参数高效型 MoE 方法(MoV 和 MoLORA)的零样本性能,其中基础模型是 T5-3B。
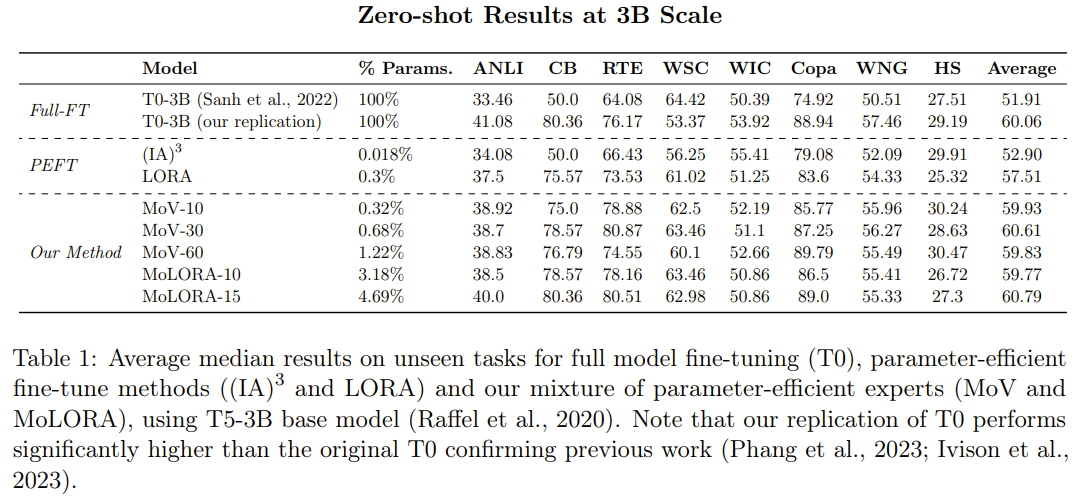
可以观察到,相比于标准的 (IA)³ 向量和 LORA 适应器,MoE 变体(MoV 和 MoLORA)的性能有显著优势。
比如,使用 30 个专家的 MoV 的表现优于密集型 (IA)³ 方法 14.57%,使用 15 个专家的 MoLORA 则在平均中值分数上提升了 5.70%。
在同样的参数负载下,MoV 的表现胜过 MoLORA。研究者也比较了新提出的两种方法:使用 3B 参数的基础模型时,MoV 在性能与参数成本的权衡方面表现更好。
参数高效型 MoE 与完全微调方法的对比。如表 1 所示,与完全微调的 T0-3B 相比,使用 10 个专家的 MoV 和 MoLORA 的性能相当。这是一个非常亮眼的结果,因为 MoV-10 仅更新了全体模型参数中的 0.32%。而如果将 MoV 的专家数增至 15,将 MoLORA 的专家数增至 30,新方法的效果甚至能小幅胜过完全微调方法。
此外,研究者还通过实验探索了参数高效型 MoE 随基础模型大小增长的性能变化情况、专家数量对下游任务性能的影响、最优的路由策略等方面,详见原论文。
相关:
大模型的最大bug,回答正确率几乎为零,GPT到Llama无一幸免我让 GPT-3 和 Llama 学会一个简单的知识:A 就是 B,然后反过来问 B 是什么,结果发现 AI 回答的正确率竟然是零。这是什么道理?近日,一个叫「逆转诅咒」(Reversal Curse)的新概念成为了 AI 圈热议的话题,现在流行的所有大语言模型全部都中招了。面对简单到不能再简单的问题,它们的准确率不仅是接近为零,而且看不出有增加正确率的可能性。而且,研究人员发现,这个大 bug 与模型体量,问的问题什么的都没..
李在明中断为期24天的绝食,开始接受治疗【环球网快讯】韩联社23日刚刚消息称,韩国最大在野党共同民主党党首李在明于23日中断了为期24天的绝食,并正式开始接受恢复治疗。图为9月22日,绝食第23天的李在明,图源:韩媒李在明现年59岁,8月31日开始“无限期”绝食,抗议总统尹锡悦的施政。绝食抗议19天后,李在明于9月18日因健康状况恶化被送入医院。医疗人员和不少共同民主党人劝说李在明停止绝食,被他拒绝。医疗人员说,绝食10至14天后,健康会受到不可逆转的损害。..
美国汽车工人大罢工升级:再增38地,已造成16亿美元损失当地时间2023年9月22日,美国密歇根州,美国汽车工人联合会工人在Stellantis工厂外罢工示威。 澎湃影像 图美国汽车工人罢工潮进一步扩大,涉及汽车三巨头中的通用汽车和标致雪铁龙母公司Stellantis。据央视新闻,当地时间9月22日,美国汽车工人联合会(UAW)主席肖恩·费恩(Shawn Fain)表示,该联合会工人的罢工将扩大至全美范围内,新一批罢工工人将在全美20个州的38个地点进行罢工。费恩在演讲中介绍,由于工会与福特的谈..
印度、加拿大,干上了!难的是,美国。正解局(ID:zhengjieclub)出品美国有几个资深铁杆小弟,加拿大绝对算一个,连领空由北美防空司令部管辖。这两年,印度也是积极向美国靠拢。美国很得意,加拿大是自己后院小弟,印度是自己在亚洲打入的一枚楔子。加拿大、印度很高兴,毕竟有了美国这座大靠山。都是大哥的小弟,按道理说,应该和睦相处才对。但是,最近出问题了:加拿大和印度干上了!要说这个事情实际上也不复杂。直接原因,是一个加拿大人,当街..
白宫新设枪支暴力预防办公室,控枪玩真的还是虚晃一枪?当地时间22日,美国总统拜登宣布成立美国有史以来第一个白宫枪支暴力预防办公室,以减少枪支暴力流行问题。据路透社报道,该办公室将由美国副总统哈里斯负责。拜登称,自己“决定发出明确的信息,以表明这个问题对我和国家非常重要”。他称,每次发生大规模枪击事件后,他都会听到人们“做点什么”的请求。拜登与哈里斯(资料图) 图源:路透社拜登发表的声明中不包括新的政策倡议,但他表示,新的白宫办公室将“集中、加速和加..
AI时代下的网络文学创作:危中寻机倒逼个性化表达 中新网甘肃敦煌9月23日电 (记者 丁思)哪些新科技将为网文创作者提供助力?它对网络文学行业将带来哪些冲击和影响?中国风网文如何进行IP价值转化和海外输出?如何更好地创建网文创作品牌?22日,第十三届中国数字出版博览会网络文学创作论坛在敦煌举行,网文作家、人工智能专家、平台运营专家、企业代表等,围绕这一热点话题进行深入探讨。 图为观众体验数字科技,感受数实融合的新阅读方式。丁思 摄 “技术赋能..
西藏区内外23对新人参加山南集体民族婚礼 中新网拉萨9月23日电 (记者 赵朗)由山南市人民政府、西藏自治区旅游发展厅共同主办的“盛世边疆·爱在山南”G219特色旅游宣推暨集体民族婚礼22日在山南市启动。 图为活动现场 山南市旅发局供图 参加此次集体婚礼的新人中有来自北京、广西、长沙、重庆等西藏区外的游客,也有来自G219沿线县区的山南当地情侣,有汉族、藏族、彝族、苗族、回族等不同民族的情侣、夫妻,他们来到山南奔赴这场浪漫之旅。接下来6天,他..
狠心母亲3万元卖掉出生3天的女婴,反悔后报案自首居然有人要卖亲生孩子?据内蒙古赤峰公安消息9月15日居民钱某(化名)报案称自己出生三天的孩子被自己以三万元的价格卖了但事后她后悔了…由于嫌疑人在“交易”过程中未使用真实信息,侦查工作难度颇大。侦查员利用现有信息开展多维度调查、综合分析,迅速锁定所有嫌疑人。经四小时奋战,侦查员成功将被拐卖儿童解救,同时将嫌疑人周某(化名)、郑某(化名)、孙某(化名)、吴某(化名)四人抓获。孩子被成功寻回(来源:赤峰..
没有李佳琦,商品会更便宜吗?李佳琦“祸从口出”之后,不止是他,带货主播这个群体,乃至整个直播带货行业,都成为众矢之的。一些观点认为,主播并不创造价值,是所谓的“套利者”,消灭赚佣金的主播,商品就会更便宜。然而,这个结论果真成立吗?事实可能并非如此。之前,李佳琦未出现在直播间的几个月里,商品并没有更便宜;狂欢中的国货,也并没有提供比原售价更低的价格,甚至为了配合直播间网友玩梗而涨了几块钱。李佳琦商品价值决定商品价格,市场经济..
从多巴胺到美拉德,小红书潮流的尽头是优衣库不论时尚如何轮回,基本款总是长青。作为面向男女老少的基础款品牌,优衣库的大多数衣服无功无过,主打一个好穿。但它也正在越来越变得时尚,既有小香风、辣妹 T 等单品,也能自由搭配出春夏多巴胺和秋冬美拉德的色系。身为平平无奇的基础款信徒,在受邀参加今年秋冬新品沙龙的时候,反而是看似不那么时尚的优衣库,给我上了一门关于时尚的课程。基础款的时尚规则有人说,优衣库是「搭配衣服的预备学校」。基础款好在谁都能穿..