原标题:AIGC落地门槛被打下来了:硬件预算一口气降至1/46,低成本上手Stable Diffusion2.0,一行代码自动并行
明敏 发自 凹非寺
量子位 | 公众号 QbitAI
从AI画画到NLP大模型,AIGC的落地成本被一次性打下来了!
话不多说,直接看结果:
Stable Diffusion 2.0训练/微调/推理,显存消耗最多可节省5.6倍,使硬件成本直降至1/46,一行代码即可启用;
1750亿参数大模型BLOOM单机推理,显存消耗节省4倍,硬件成本直降至十几分之一。
一行代码实现自动搜索最佳并行策略,显著降低分布式训练上手门槛,原生支持Hugging Face、Timm等热门AI模型库。

要知道,在AIGC爆火的另一面,居高不下的成本困扰着整个行业。
上周,首批AI画画公司之一StockAI被迫宣布关闭平台。原因无他,创始人表示:
公司驱动成本太高了,目前的收入难以为继。
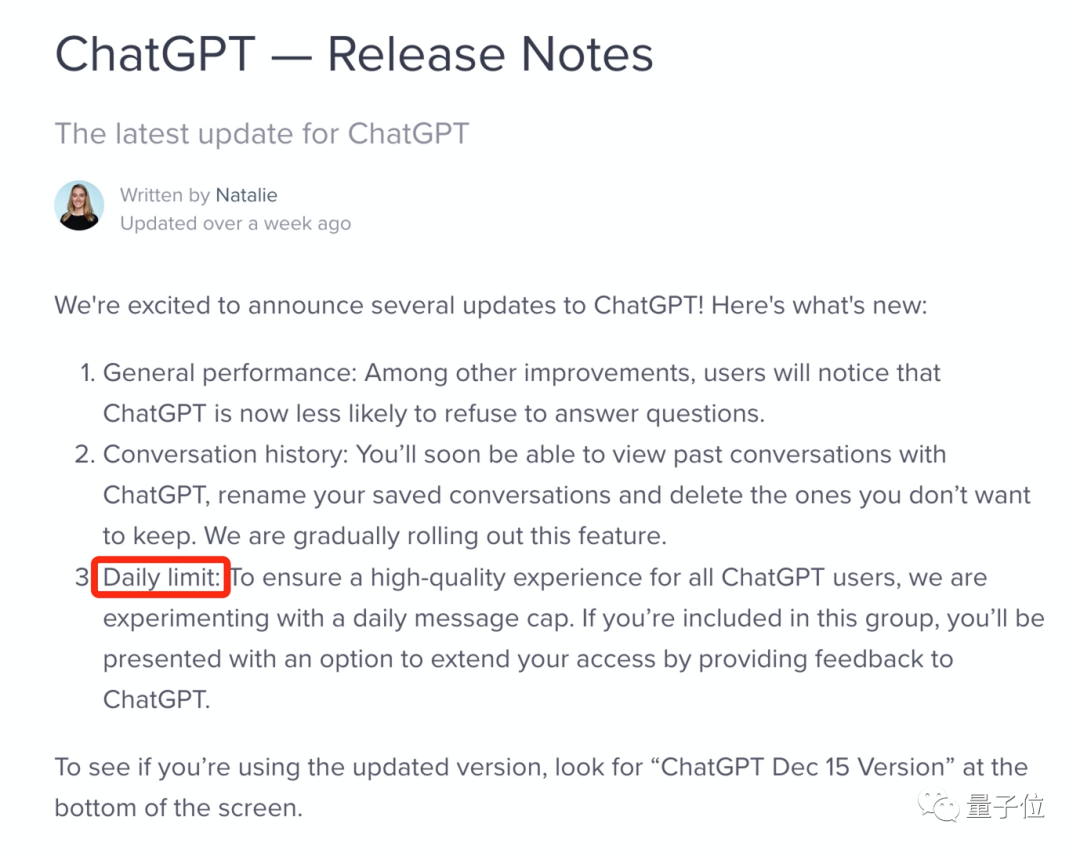
即便如ChatGPT身后有OpenAI和微软撑腰,也在平台开放几周后发出公告,开始限制用户每日使用次数。
言下之意无非四个字:烧不起了。
总而言之,降低AI大模型落地成本,是目前行业内亟需解决的问题。
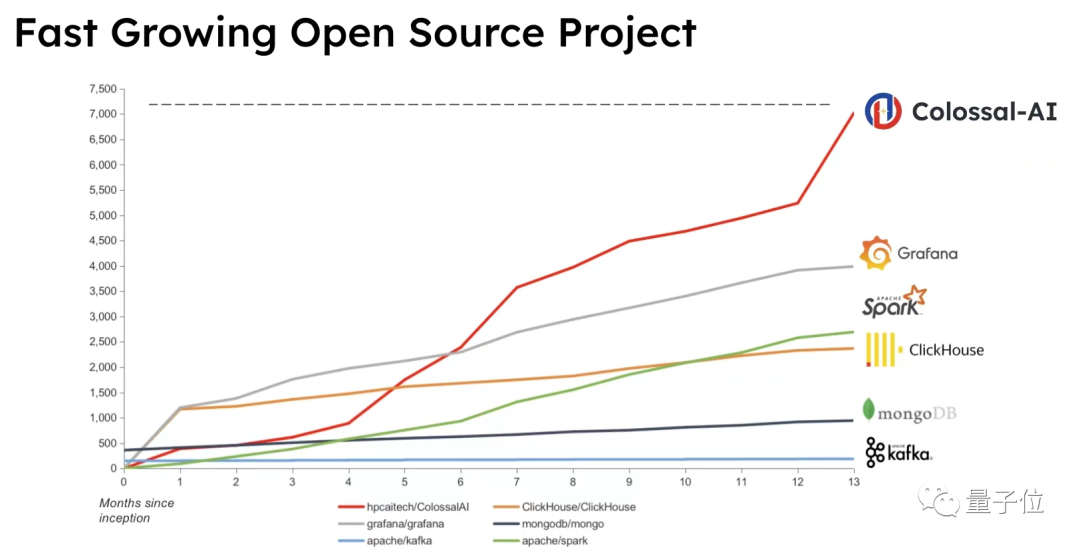
与此同时,开源AI大模型解决方案Colossal-AI在过去一年迅速蹿红,GitHub上已经收获7k+Star。
如上降本方案,便出自它之手。
具体是怎么实现的?往下看,
Stable Diffusion2.0低成本训练/微调/推理
相较于1.0版本,Stable Diffusion 2.0不仅提升了模型生成图像像素,还引入了Depth2img模型、text-guided修复模型等,功能更加完善。
这波上新其实让用户们既惊喜又措手不及。
(毕竟1.0都还没玩明白呢)
但话说回来,还是老问题,AIGC模型落地的成本高啊。
以Stable Diffusion为例,其背后的Stability AI维护超过 4000 个英伟达 A100 的 GPU 集群,并已为此支出超过 5000 万美元的运营成本。
面对快速迭代的模型、算法和下游任务,如何降低应用成本成为AIGC真正走向落地的核心问题。

Stable Diffusion 2.0基于简单易用的PyTorch Lightning框架搭建。
作为PyTorch Lightning的官方大模型解决方案,Colossal-AI第一时间进行跟进。
具体内容有以下几点:
显存消耗可节省5.6倍,硬件成本最多降至1/46
支持DreamBooth单GPU快速个性化微调
推理显存消耗节省2.5倍
而且该方案也将于近期合并进入Hugging Face,进一步方便用户使用。
训练
为了加快训练速度,降低训练成本,使用更大的batch size已成为被广泛使用的有效手段。但GPU有限的显存容量,严重限制了batch size大小,推高了训练硬件门槛。
通过一系列显存优化技术,Colossal-AI使得Stable Diffusion平均在每个GPU上使用大batch size 16训练的显存需求,从64.5GB降低到了11.6GB、节省5.6倍,还可扩展至单GPU或多GPU并行。
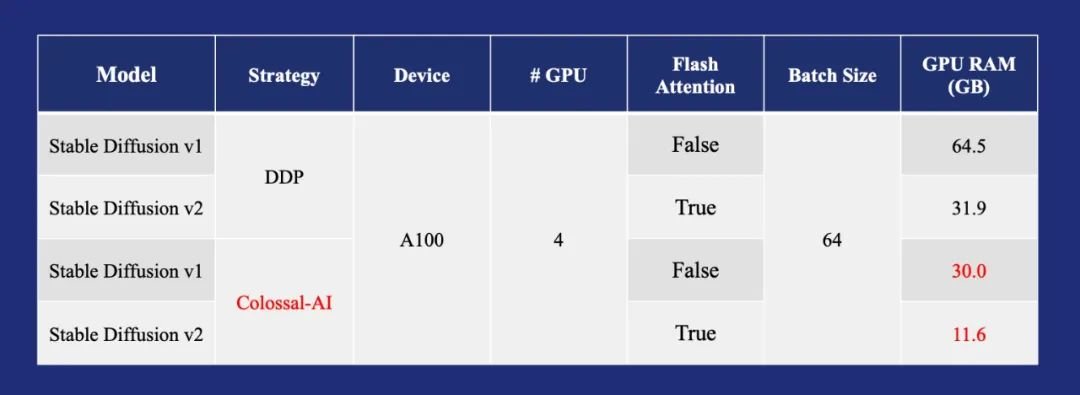
相比使用最先进的A100 80GB,目前仅需3060等消费级显卡即可满足需求,硬件成本最高直降至1/46。
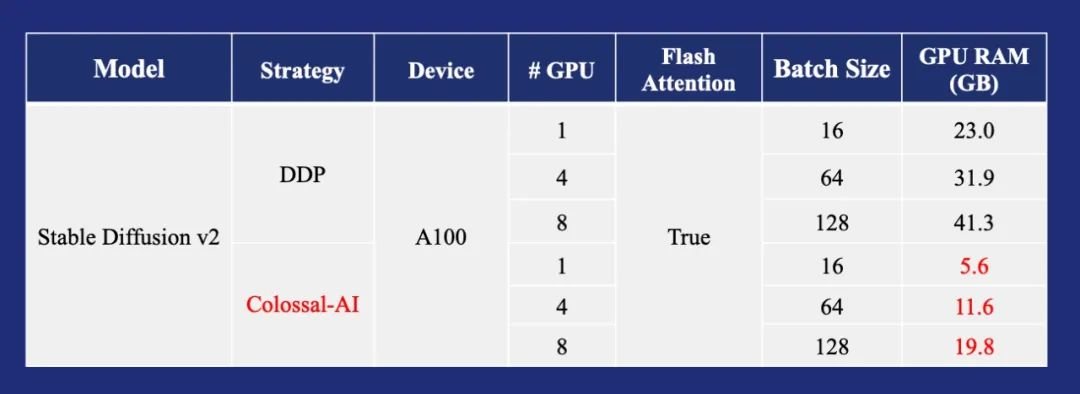
由此可以让更多用户在消费级GPU上,低成本地开展Stable Diffusion的相关研究与应用落地。
背后显存优化 Flash Attention
早在Stable Diffusion 1.0版本,Colossal-AI就率先引入了Flash Attention技术,成功将attention的速度提升 104%,将端到端训练的峰值显存减少 23%。
Flash Attention是针对长序列 attention 的加速版本,使用 Flatten 来减少 GPU 高带宽内存(HBM)之间的内存读 / 写次数,Flash attention 同时针对块状稀疏的 attention,设计了一个近似的注意力算法,比任何现有的近似 attention 方法都要快。
在Stable Diffusion 1.0版本,整个Diffusion Model只有少量attention层,Flash attention还没有体现出其性能优势。
在Stable Diffusion 2.0中,由于将大量卷积层替换为attention层,进一步发挥了Flash Attention的显存优化潜力。
ZeRO + Gemini
Colossal-AI支持使用零冗余优化器(ZeRO)的方法来消除内存冗余,与经典的数据并行性策略相比,可极大提高内存使用效率,同时不牺牲计算粒度和通信效率。
此外,Colossal-AI 还引入了Chunk机制进一步提升ZeRO的性能。
运算顺序上连续的一组参数存入一个Chunk中(Chunk即一段连续的内存空间),每个Chunk的大小相同。
Chunk方式组织内存可以保证PCI-e和GPU-GPU之间网络带宽的高效利用,减小了通信次数,同时避免潜在的内存碎片。
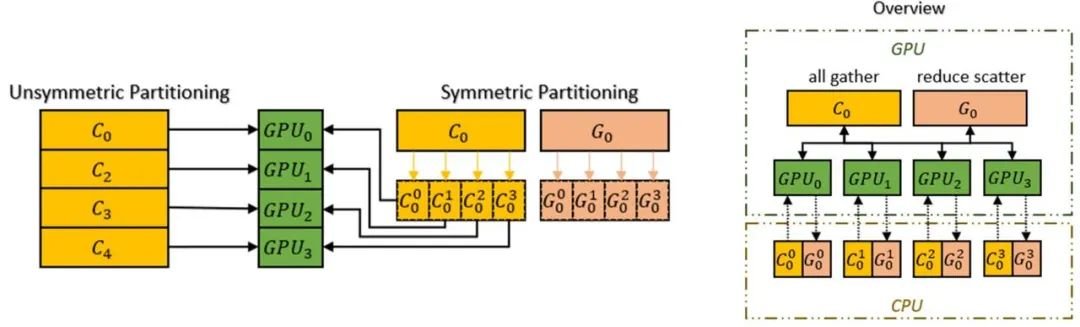
而Colossal-AI的异构内存空间管理器Gemini支持将优化器状态从GPU卸载到CPU,以节省GPU内存占用。
可以同时利用GPU内存、CPU内存(由CPU DRAM或NVMe SSD内存组成)来突破单GPU内存墙的限制,进一步扩展了可训练模型规模。
一行代码快速上手
作为PyTorch Lightning的官方合作伙伴,仅需一行代码即可调用Colossal-AI的上述显存优化。
DreamBooth微调
在推出Stable Diffusion 2.0加速方案的同时,Colossal-AI还“顺手”发布了DreamBooth模型的微调方案。
这是谷歌在今年8月发布的模型。它只需3-5张图片,再加上文字表述,就能让指定物体迁移到其他场景或风格中去。

和Dall-E 2、Imagen等最大的不同是,DreamBooth能对选定对象忠实还原。
方案中,用户只需直接运行文件train_dreambooth_colossalai.py,即可在该微调任务上充分发挥Colossal-AI的显存优化,个性化快速微调自己的图文模型,极大降低使用门槛。

推理
由于模型推理对数值精度不敏感,这为实现低精度的低成本推理提供了可能。
对于Stable Diffusion 2.0模型,可以通过添加一行代码,支持模型的Int8量化推理,显存消耗节省2.5倍,仅需3.1GB,且不造成显著性能损失。
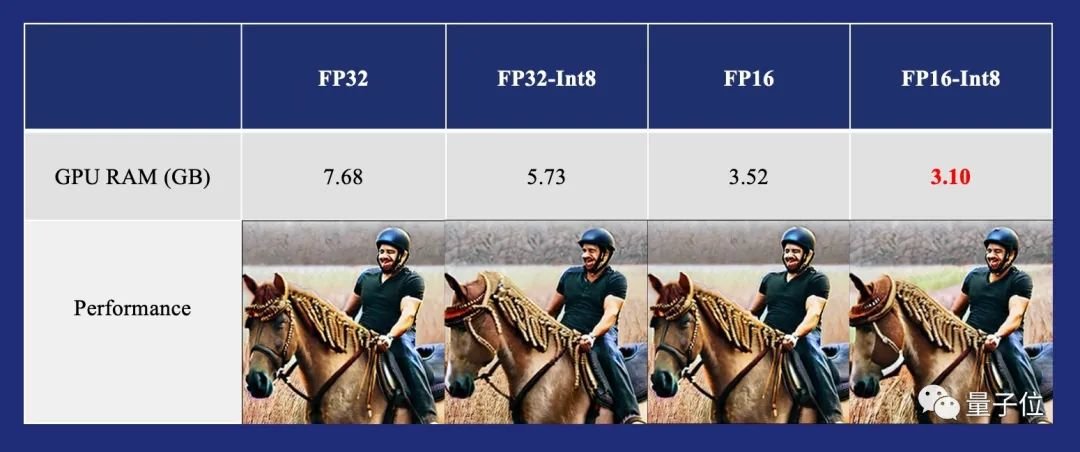
用RTX3090推理1750亿BLOOM模型
AI画画爆火的另一边,NLP大模型的趋势也还在延续。
今年7月,Hugging Face发布了1750亿参数开源模型BLOOM,它动用384块A100炼成。
如果直接使用常见的FP32/FP16进行推理,在单节点8张GPU使用模型并行,每张GPU需要消耗至少87.5GB/43.8GB的显存。
如此大的显存占用,即使是最先进的8卡A100(80GB/40GB)服务器,也无法直接部署推理服务,而多节点推理又会带来沉重的额外成本和通信开销。

基于这一现状,Colossal-AI实现了高效的Int8量化和模型并行推理,可以将1750亿参数的BLOOM等大模型的推理服务,部署到3090/4090等消费级显卡的8卡服务器,同时不产生显著的CPU内存占用提升及性能损耗。
相比原有的A100方案,可将硬件部署成本降低到原有的十几分之一。
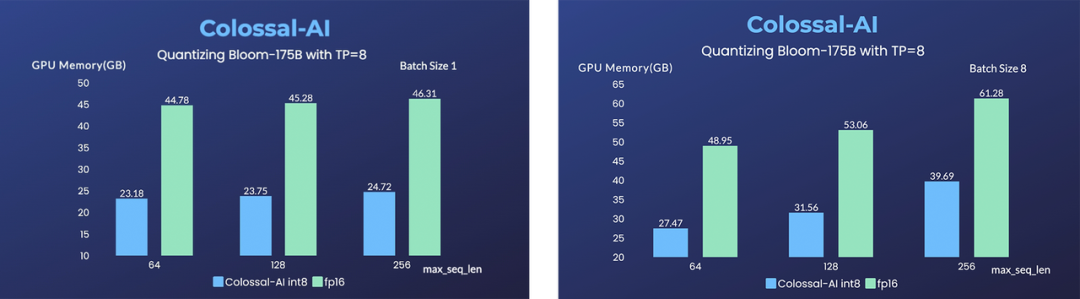
通过对模型进行Int8量化,Colossal-AI可将模型总体显存占用从352.3GB(FP16)降低到185.6GB, 同时使用Colossal-AI的模型并行技术,将每张显卡的占用减少到了23.2GB。
在模型并行中,为了不增加CPU内存占用,Colossal-AI在主进程中进行模型的量化和切分工作,其余的每个进程中分别使用lazy_init获得几乎不占显存和内存的meta model,再通过gloo backend在进程之间传递模型参数。
通过上述方案,在没有分段加载模型参数的情况下,便可以使得CPU内存占用峰值,达到理论上的较优水平。相较于将模型按层切分的“类流水线”分布方式,模型并行可以提高非密集请求下的显存使用效率。
一行代码自动并行
大模型的分布式混合部署是一个非常复杂的问题。
目前常见的分布式大模型训练方案,都依赖于用户人工反复尝试以及系统专家基于经验进行配置部署。
然而,这对于绝大多数AI开发者来说很不友好,因为大家都不希望把过多时间精力花费在研究分布式系统和试错上。
由此,Colossal-AI的高效易用自动并行系统,可以说是解大家燃眉之急了。
仅需增加一行代码,它就能提供cluster信息以及单机训练模型即可获得分布式训练能力,并且原生支持包括Hugging Face,Timm等热门AI模型库。
因此,Colossal-AI可以极大地降低AI开发者的使用分布式技术训练和微调大模型门槛。同时,自动并行系统可以从更细粒度搜索并行策略,找到更加高效的并行方案。

Graph Tracing
Colossal-AI是首个基于PyTorch框架使用静态图分析的自动并行系统。
PyTorch作为一个动态图框架,获取其静态的执行计划是机器学习系统领域被长期研究的问题。
Colossal-AI使用基于torch.FX Tracer的ColoTracer,在tracing过程中推导并记录了每个tensor的元信息,例如tensor shape,dims,dtype等,可以为后续的自动并行策略搜索提供帮助。
因此Colossal-AI具有更好的模型泛化能力,而不是依靠模型名或手动修改来适配并行策略。
细粒度分布式训练策略搜索
Colossal-AI会在满足内存预算的限制下,以最快运行时间为目标,为每个op进行策略搜索,最终得到真实训练时的策略,包括每个tensor的切分策略,不同计算节点间需要插入的通信算子类型,是否要进行算子替换等。
现有系统中的张量并行、数据并行,NVIDIA在Megatron-LM等并行系统中使用的column切分和row切分并行等混合并行,都是自动并行可以搜索到的策略的子集。
除了这些可以手动指定的并行方式外,Colossal-AI的自动并行系统有能力为每个op指定独特的并行方式,因此有可能找到比依赖专家经验和试错配置的手动切分更好的并行策略。
分布式tensor与shape consistency系统
与PyTorch最新发布的DTensor类似,Colossal-AI也使用了device mesh对集群进行了抽象管理。
具体来说,Colossal-AI使用sharding spec对tensor的分布式存储状态进行标注,使用shape consistency manager自动地对同一tensor在不同sharding spec间进行转换。
这让Colossal-AI的通用性和易用性极大地提升,借助shape consistency manager可以没有负担地切分tensor,而不用担心上游op的output与下游的input在集群中的存储方式不同。
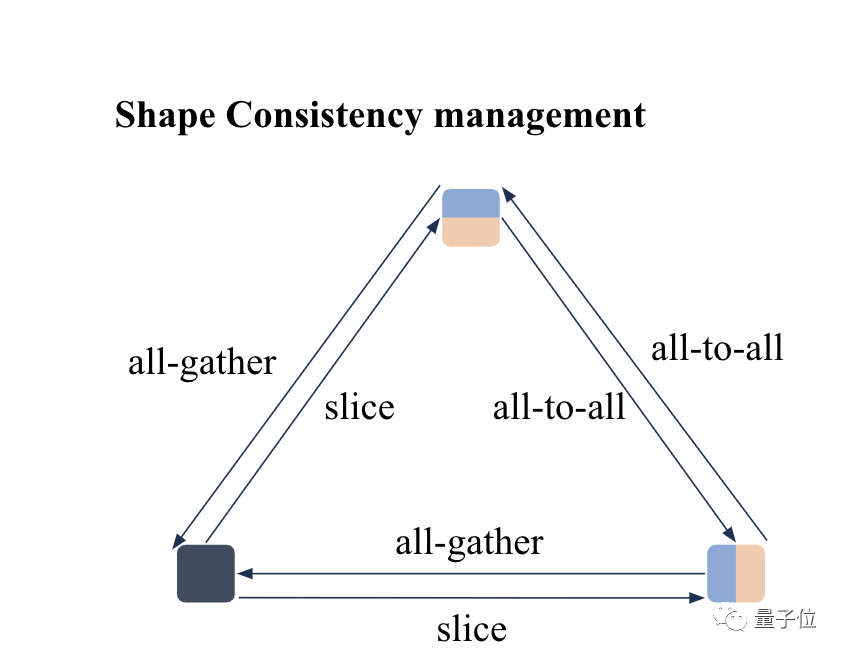
相较于PyTorch DTensor,Colossal-AI有以下3个优势:
Colossal-AI的device mesh可以profiling到集群性能指标,对不同的通信算子进行耗时估算。
Colossal-AI的shape consistency会贪心地搜索sharding spec间的转换方式,而不是朴素地逐dimension进行转换,这样能找到更高效的转换路径,进而使得sharding spec间的转换通信开销更小。
加入了all_to_all操作,使得Colossal-AI的扩展性更强,这在大规模集群上进行训练时,可以展现出很大的优势
与activation checkpoint结合
作为大模型训练中必不可少的显存压缩技术,Colossal-AI也提供了对于activation checkpoint的自动搜索功能。
相比于大部分将最大显存压缩作为目标的技术方案,Colossal-AI的搜索目标是在显存预算以内,找到最快的activation checkpoint方案。
同时,为了避免将activation checkpoint的搜索一起建模到SPMD solver中导致搜索时间爆炸,Colossal-AI做了2-stage search的设计,因此可以在合理的时间内搜索到有效可行的分布式训练方案。
关于Colossal-AI
通用深度学习系统Colossal-AI面向大模型时代,它可实现高效快速部署AI大模型训练和推理,降低AI大模型应用成本。
自开源以来,Colossal-AI已经多次在GitHub热榜位列世界第一,获得GitHub Star超七千颗,并成功入选SC、AAAI、PPoPP等国际AI与HPC顶级会议的官方教程。
Colossal-AI相关解决方案已成功在自动驾驶、云计算、零售、医药、芯片等行业知名厂商落地应用,广受好评。
例如近期爆火的ChatGPT,尚未开源且不具备联网功能。Colossal-AI已成功帮助某世界500强企业,开发具备在线搜索引擎能力增强的聊天机器人模型。
,AIGC落地门槛被止回阀厂家 打下来了:硬件预算一口气降至1/46相关:
英伟达再扩元宇宙版图!助攻奔驰打造数字孪生工厂作者 | ZeR0编辑 | 漠影智东西1月4日报道,今日,NVIDIA(英伟达)在CES期间宣布推出Omniverse Enterprise协作平台的最新版本,并宣布其用于简化交互式虚拟形象开发的云原生AI微服务NVIDIA Omniverse Avatar Cloud Engine(ACE)现可供抢先体验。Omniverse Enterprise最新版本提供了更高的性能和可用性、全新部署选项和全新Omniverse Connectors,在实时RTX光线和路径追踪方面实现了代际飞跃,简化了工作流,可助力团..
年轻人抛弃了电热毯作者:王明雅 | 编辑:葛伟炜“‘取暖神器’哪家强?”题图源自韩剧《请回答1988》每年的12月份,是南、北方鄙视链的转向时刻。冷空气来袭,全国迎来大幅度降温,北方潇洒进入供暖期,而在湿潮冷空气里颤抖的南方人,只能投去艳羡的目光。好在,取暖神器能稍稍扳回一城。来自北京的消费者高宁(化名),每年都会为南方家乡的父母添置过冬设备,从常见的电暖器、足浴桶,到某些服装品牌宣传的HEATTECH“高科技”内衣,能想到的..
这些微软Office功能和产品将于2023年退出舞台IT之家 1 月 4 日消息,国外科技媒体 Borncity 在最新文章中,分享了一些要退出微软 Office 舞台的功能和产品。在功能方面则主要是 Transfer Files 和 Share Nearby 两项功能,而在产品方面,Office 2013 将于 4 月停止支持。Transfer Files 和 Share Nearby 两项功能退休正如在今年 11 月所预告的那样,微软已经移除了 Transfer Files 和 Share Nearby 两项功能。微软希望通过精简冗余功能,添..
CES前瞻:新U加新卡 今年游戏笔记本实力不容小觑一年一度的CES马上就要开幕了,在经历了受疫情影响而格外冷清的CES 2022后,全球规模最大消费电子展——CES 2023目前已经准备就绪,并将于明年1月回到拉斯维加斯,作为数码产品爱好者最期待的电子展之一,与展商、媒体和专业观众见面。图片来源:ces.tech根据官方介绍,CES 2023将迎来约2400家参展商——包括谷歌、亚马逊、微软、高通、LG、三星、索尼、松下和哈曼,他们将于1月5~8日在拉斯维加斯参与展会。如果你无法抵达现..
苹果Apple Pencil新专利曝光 可以从真实世界的表面采样颜色苹果已经为下一代Apple Pencil申请了专利,它可以从现实世界中采样颜色,然后将相同的颜色输入iPad,以及其他功能,包括对纹理进行采样的能力。该专利由PatentlyApple报道,描述了一种Apple Pencil,铅笔尖端内置了颜色传感器,可以对现实世界物体的表面进行采样并检测其颜色。专利中的图像显示,Apple Pencil可能带有内置的光环境传感器,光发射器和可以检测表面颜色和纹理的光检测器。与所有专利一样,它不会透露这样的功能..
曝2024年苹果将推mini-LED屏Apple Watch和廉价版AirPods除了概述他对今天iPhone 15阵容的期望外,技术分析师Jeff Pu表示,苹果可能会在2024年发布两款值得注意的产品,包括第一款带有micro-LED显示屏的Apple Watch和价格较低的AirPods。在香港投资公司海通国际证券的一份研究报告中,浦志强表示,新的高端Apple Watch可能会采用更大的2.1英寸micro-LED显示屏,与目前配备OLED显示屏的Apple Watch型号相比,这将增加亮度。该型号可能是Apple Watch Ultra的新版本,该版本于去年9..
王者和原神都没进榜 全球热门移动游戏下载量榜单出炉近日,知名调研平台Sensor Tower公布了11月份全球人们移动游戏下载量Top 10。其中Miniclip旗下SYBO Games《Subway Surfers 地铁跑酷》以1770万次下载,位列11月全球移动游戏下载榜榜首。印度是该游戏第一大市场,贡献了18.3%的下载量;其次是巴西,占8.7%。全球热门移动游戏下载量TOP10完整榜单请见上文图表。注:下载量仅统计App Store和Google Play,不包括第三方安卓市场。DINO《Shotgun Sounds》以1720万次下载排名..
印度将生产45-50%的iPhone 与中国制造“平分秋色”“印度制造”正在崛起,未来将来会有越来越多的iPhone产自印度。1月4日消息,据DIGITIMES Research分析师Luke Lin估计,到2027年印度将生产45-50%的苹果iPhone。该分析师表示,虽然2022年底印度组装产能占iPhone整体产能的10-15%,但到目前为止印度的实际产量还不到5%。iPhone 14 Pro系列这也就意味着,印度制造的iPhone将会越来越多,中国制造的iPhone可能会越来越少。据悉,2022年中国负责生产80-85%的iPhone。按照上述分..
好评率99%!OPPO Find N2好用在哪?看看真实用户怎么说对于有打算换手机的朋友来说,相信购机时除了会看手机的配置之外,一定还会去看看用户评价,毕竟用户评价一般都是大家真实上手后的实际感受,可以比较好地反映一台手机的真实表现,对购机很有帮助。比如最近OPPO Find N2系列就凭借全面的配置、独到的体验吸引了消费者的关注,很多人都想知道它实际体验究竟是不是和宣传一样好用。那么趁着这个机会,我们就不妨一起来看看大家对OPPO Find N2系列的评价如何吧。(左:OPPO Fi..
曾称污染比燃油车更大!丰田章男再度质疑电动车丰田潜心几十年研究的油电混动HEV、氢燃料电池汽车FCV,在当前汽车电动化时代,甚至被直接跳过,始终没有得到大规模的推广应用。这或许也是丰田不甘心直接转型电动化时代的原因,为此,丰田掌门人丰田章男,不止一次表达了对电动车的质疑。近期,丰田章男再次质疑纯电动汽车,他表示“电动汽车并不是世界碳中和目标的唯一途径。”丰田章男认为,消费者和汽车制造商也对电动汽车彻底达到世界碳中和持怀疑态度,但不愿意公开表态,..