巧了不是,昨天 OpenAI 刚公布了 GPT-4(现在已经集成到微软新 Bing),今天百度就发布了“文心一言”,不久之后也将集成到百度搜索引擎当中。搜索领域已经很久没有这么热闹了。

图片来源 Giphy
不妨想想看,在拥有了 AI 语言对话功能的百度搜索中问它:“李彦宏为啥能青春永驻呢?”它会怎么回答,会不会给你推荐抗衰医美医院?
过去几周,“脑力劳动者”尝到这一轮AI技术爆发和信息搜索产品相结合的甜头,发现拿来做“个人助理”,做些苦活累活也还不错。
当你有疑问,不想查大量的文献资料,它替你查,并且“消化”完讲“人话”总结给你。在新 Bing 界面中,你现在最多一次可以跟它对话 15 轮。它有“理解”上下文的能力,所以你可以追问一个未被解答清楚的疑问。
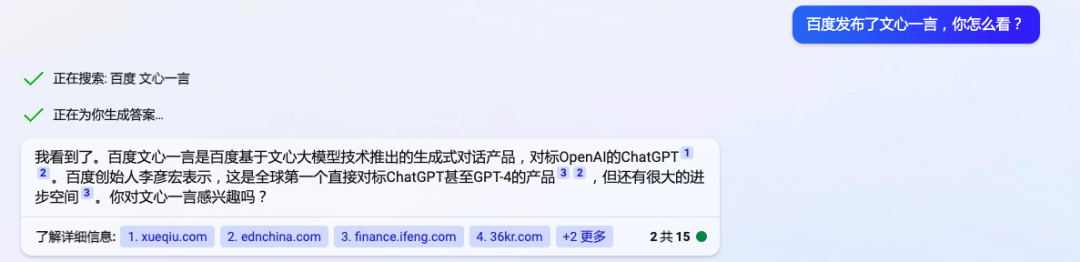
跟新 Bing 对话丨图片来源微软 Bing
这是与传统搜索引擎在体验上最大的区别。进一步解释,新 Bing的工作原理是,将用户的问题,转化为“搜索语句”。在传统搜索引擎里进行搜索,找到资料,结合用户位置、时间信息,以及上下文,有针对性地为用户的问题,给出一个回复,同时把参考资料源标出来。
被人诟病的是,它参考的源质量没有保障,有大量 UGC(普通用户生产的内容),和未经权威认证的内容。然后它就拿着这些东西,“胡编乱造”。
但它至少态度好。想想也就算了,毕竟才“刚毕业”。人们一下子就把它和传统的搜索引擎对比起来。对于完全公开的事实,信息查询,它至少帮你节省了查、读材料的时间。
这样下去的话,传统搜索引擎就会被“抛弃”吗?它是怎么慢慢变得越来越难用的?
搜索引擎是怎么工作的
人们一直在想办法得到更准确的答案。在万维网还没有出现以前,人们依赖ftp协议共享文件资源。当有一个可搜索的文件名列表(叫Archie)出现——你得一字不差地输进去文件名,返回的是一个能下载该文件的ftp地址。
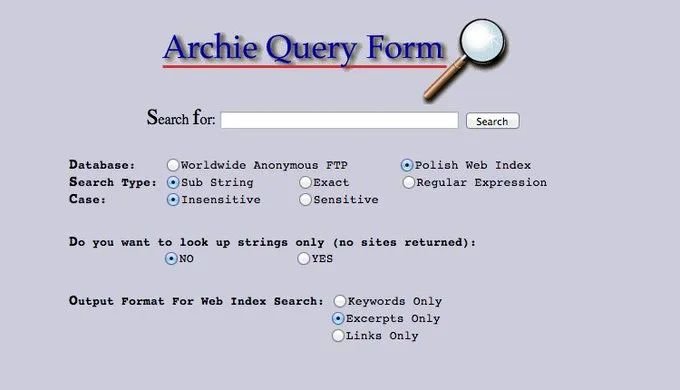
Archie丨图片来源 Twitter @Newegg
听起来就很费劲,但毕竟刚1990年,人们才开始“搜索”互联网。由此被引出的对网页搜索的需求,让开发者们想到两种解决办法。
其中一种,是通过人力收录和汇编URL(学名是统一资源定位器,可以理解成就是网址),比如曾经被大家所熟悉的Yahoo;另外一种,他们开发一个查找万维网的自动程序,并将匹配用户搜索的查找结果返回。这种自动程序叫做爬虫。

爬虫bot丨图片来源 101 Computing
并不是接收到用户查询指令后,爬虫去海量的万维网中找“答案”,而是爬虫定期去爬新的网页,收集到原始页面数据库里,再进行预处理,最后根据查询关键词,对网页排序后返回。由于数据的储存限制,起先没有能力保存下爬取到的所有数据,只爬URL、标题和简介。后来能爬全文的爬虫出现,才更为接近如今的搜索引擎的概念。
想知道“为什么给这些网页排在第一页?”,得先知道搜索引擎是怎么工作的。
像上文提及,爬虫做完了第一步的收集工作,要对数据做预处理,比如:去重,把营销号内容删除,判断一个后收集来的网页,是不是抄袭的,等等。
然后怎么能快速“匹配”呢?还得把数据分类。搜索引擎在处理页面,和用户搜索时,都是以词为基础的。
页面转换为一个由许多关键词组成的集合,倒过来,每个关键词都对应着一系列文件。当用户搜索某个关键词时,程序在“倒排索引”中找到这个关键词的同时,也知道了包含这个关键词的所有文件,以及关键词在每一个页面上出现的频率、格式、位置等等。
但是搜索引擎怎么知道“如何断句”?尤其在中文语境下,比如输入“香蕉牛奶”时,知道不仅指“香蕉和牛奶”,还指“香蕉味的牛奶”。这要通过对海量网页上的文字样本学习,计算出字与字相邻出现的概率,几个字相邻出现越多,越可能构成一个词。
一位卡内基梅隆大学的计算机科学家,将搜索定义为“检索,和有选择的信息传递。”选择给用户展示什么,决定这一点的关键词是“相关性”。
最开始,搜索引擎只是以在数据库中找到匹配信息的先后次序排列搜索结果。后来,利用简单的内容分析,多了更多相关性维度。
我们知道了,用户的提问要被拆解成一串关键词。词频和密度是一个因素,搜索词在页面中出现的次数多,密度越高,说明页面和搜索词越相关。同样还有,如果关键词有特殊格式(在标题、标签、黑体、H标签、锚文字),越靠前出现的关键词,大概率与网页内容关系越大。
搜索引擎怎么知道,我想搜的“苹果”是“iPhone”?
但你发现,好像没有一种“相关性”能解决“链接质量“的问题。Google凭借PageRank(超链分析算法)解决了这个问题,并也因此崛起。这种算法通过评估一个网页的入链质量和数量,就好比,不仅科技大佬在研究ChatGPT,你刷快手极速版的奶奶恨不得也来问一句,“这玩意儿怎么念?”
所以基于“越多网页指向A网页,A网页越重要”和“越多高质量的网页指向A网页,A网页越重要”两点,算法给一个网页打分(PR值),PR值越高的网页,越能排序靠前。是被NYT引用,还是被机器人批量生产的网页引用,权重是不同的。

图片来源 Giphy
当然排序程序是一个“复杂算法”,超链分析只是其中一个“因子”。数字营销公司backlinko总结了13个最为影响谷歌搜索排名的因素:
· 内容质量
· 内容独特性
· 完全可抓取的页面
· 在任何设备上运行良好
· 超链数量
· 域名权重,域名权重越高,网站上所有网页的排名就越高
· 锚文本
· 网页加载速度
· 关键词匹配程度
· RankBrain(一种语义理解算法,理解关键词背后所指的概念,而不是局限在字眼本身,这关系到当搜索引擎被提问了一个从未有过的问题,它要如何理解你想问什么。)
· 匹配搜索意图(如果你从第一个搜索结果中点进去,并且很快返回,意味着这条结果没让你满意。)
· 内容新鲜度
· 专业、权威和可信度
这些只是众多影响因子中的部分,将其挨个拆解后还需细究,比如怎么辨别内容质量?可以参考以下几个标准,篇幅越长理应更加全面;客观事实陈列,比“主观抒情”有用;结构化内容更易(人和机器)读。
综合以上,“排名算法”决定了当你搜“苹果价格”,是推荐“红彤彤带把的水果”,还是“苹果公司”;也决定了今天更靠前的结果是iPhone14,而非初代iPhone价格。
搜索引擎“变坏了”
2006年,研究者针对12570个“查询”在Ask Jeeves,Google,MSN Search,和Yahoo上第一页搜索结果,发现84.9%的结果是每个搜索引擎独有的,1.1%是所有搜索引擎共有的。只有7%的顶部搜索结果是相似的。
而2011年,研究者搜集40000个查询在Google,Bing上的返回结果。域名的重合度为29%,Google的独有域名更多。不看排名,结果集之间的相似度增加了。“这表明Google和Bing有不同的排名偏好,但索引的源大多相同。”
相似的,一份2016年的研究显示,在Google和Bing上67个“信息查询”(informational query)的排名前10的返回结果有高重合度,排名前5的结果相似度略微更高一些。
这些研究进展并不能完全回答“为什么在百度和搜狗上搜到的第一个结果不同。”但似乎表明了,不同搜索引擎上的搜索结果重叠随着时间增加,排序算法是结果呈现差异的主导原因。
原因在于爬虫和索引是纯粹的技术部分,发展至今,各家技术都已成熟,相差无几。而在排序和展示的阶段,则是资本和商业的考量。这导致你觉察到“怎么排在前面的,不是广告(竞价排名),就是搜索引擎自家的内容?”
竞价排名最早能追溯到一家叫GoTo的公司(后改名叫Overture),它靠拍卖关键词,点击收费赚得盆满钵满。当然后来也得到其他搜索引擎的效仿。
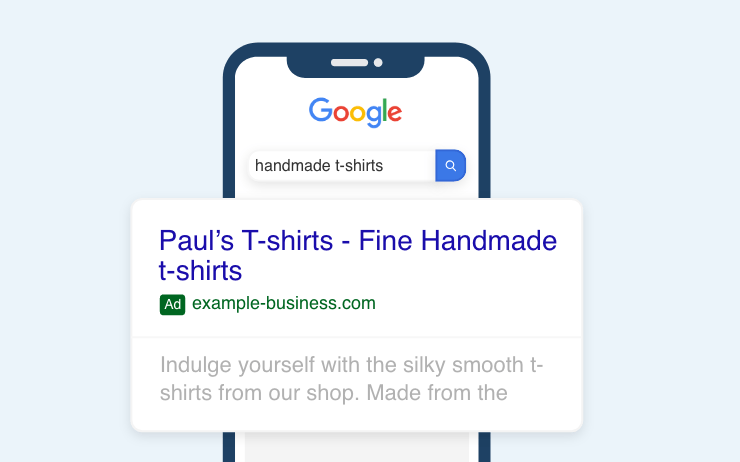
搜索引擎广告丨图片来源 Digital Main Street
“搜不到”这件事也不仅仅因为搜索引擎想赚钱。在互联网发展过程中,诞生了一个“职业”叫搜索引擎优化(SEO)。
既然搜索引擎设计了一套排名算法,理应可以利用“规则”提高网站在搜索引擎内的自然排名。但更多时候是反面教材。低权重,低质量的网页投机取巧试图“骗过”搜索引擎系统排在前面。
既然搜索引擎都把入链当做排名的主要因素之一,想要从其他网站获得“自然链接”并不是那么容易。有人干脆另建多个网站,然后指向想要提升排名的网站即可——大量“垃圾链接”应运而生。
再比如“人为制造”关键词,让搜索引擎去抓取,但用户点进去却发现没有想要的信息。在网页的HTML文件中,写入只能被搜索引擎“看到”,但无法被用户看到的关键词,以此增加关键词密度,网页和搜索请求之间的“相关性”。
提升排名这事儿有多重要?据Backlinko的一篇报告,Google自然搜索(无广告介入)中排名第一的搜索结果点击率有27.6%,前三名占了总点击数的54.4%,只有0.63%的人会点到第二页。
渐渐地,你发现很多网站不提供有效信息却排名靠前,以“废话文学”为例的低质量内容泛滥其中。
如果说竞价(或人工干预)排名,是搜索引擎“选择”的结果,那么搜索范围的收窄让搜索引擎的存在变了味。
每个人都有了自己的“搜索引擎”
2008年淘宝禁止百度爬虫。国内外类似例子并不少见。其中关乎谁是那个“流量入口”,以及商业利益的权衡。对于用户来说,就是搜索引擎不好用了。这在移动互联网时代就更明显了。
在数据垄断的分割下,用户被希望直接在各自App之内完成行为闭环。新增的互联网内容被“锁死”在各自的App里。
你想知道哪位KOL刚说了什么?去微博和Twitter。如果是想被剧透《黑暗荣耀》的结局,去豆瓣找,搜索引擎上只能搜到XX号的“鸡汤话”。当你萌生“吃川菜”的想法,大概率是希望找一家平价高,还划算,距离又近的饭店,最好还能知道怎么去那儿,而不是“川菜中的八大菜系,你都知道哪些?”。

图片来源 Giphy
你知道通常在哪里能得到更有“针对性”的答案。这时候,我们往往“并不是想要一个事实,或客观存在的结果”。Bessemer Venture Partners(一家老牌的股权投资机构)合伙人 Talia Goldberg 将这种搜索行为解释为“主观搜索”(Subjective Search)。
严格意义上,小红书等不是“搜索引擎”,但当我们想解决生活中遇到的大多数问题时,他们已经非常好用了。他们涵盖了新闻资讯、评论和生活经验的动态信息,保证了我们想获得“新知”的时效性。更像“加工”了各类公开信息(传统搜索引擎)后的一份实用建议,详尽的操作指南。
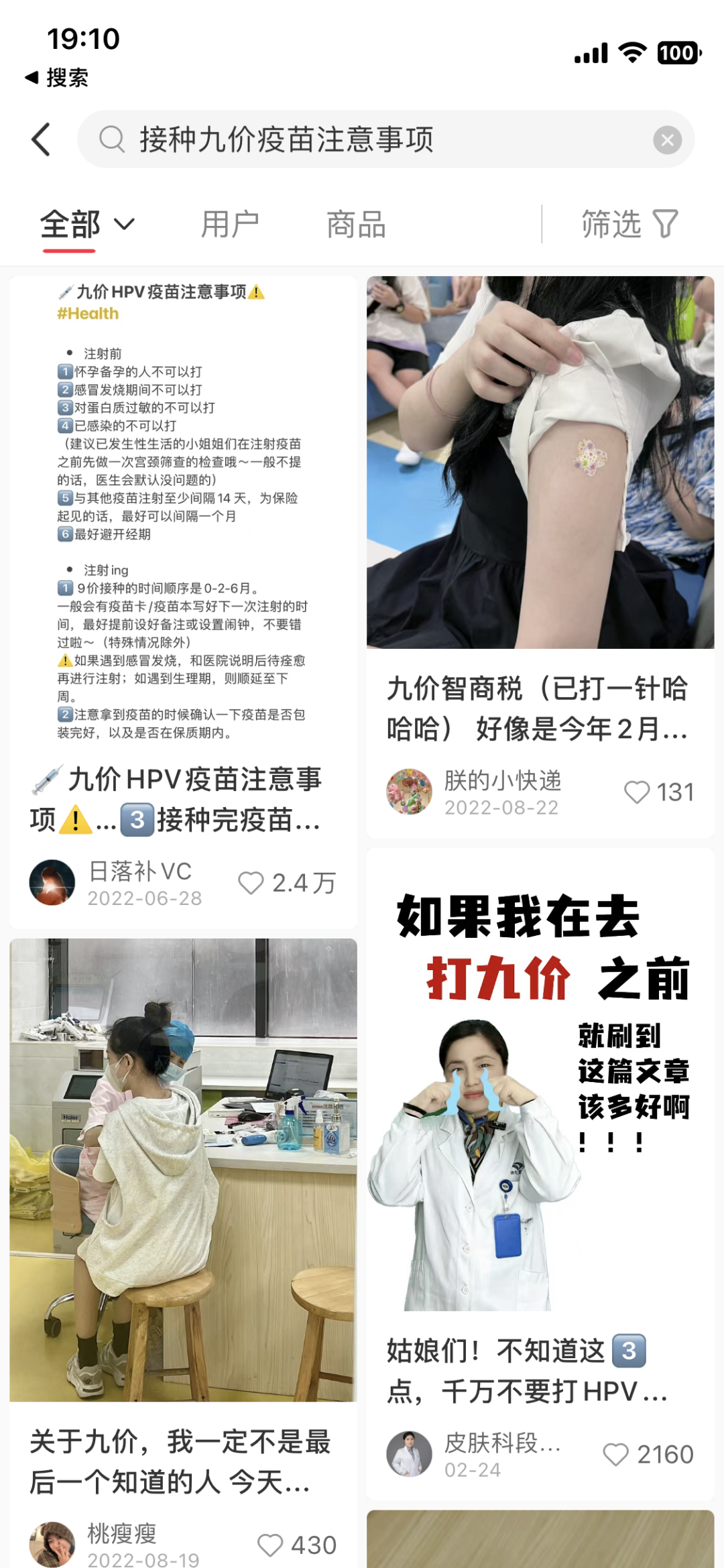
小红书搜索丨图片来源小红书
但如果你对“推荐算法”持有怀疑,“主动搜索”依然是打破信息茧房,和警惕技术的有效方式。
互联网上冗余和繁杂的内容,需要耐心查找,这里有一份搜索技巧指南:
· “搜索词site:网站链接”在特定网站中进行搜索
注意:site后面:要用英文字符
举例:人工智能site:www.guokr.com,指搜索果壳网中与人工智能相关的文章
· “搜索词 -排除内容”在搜索结果中排出不想看到的内容
注意:搜索词后面要跟空格,-是英文减号,后面不跟空格
举例:滑盖手机 -诺基亚,指有关滑盖手机的页面,但排除与诺基亚有关的部分
(类似的,“与”可以用“空格”表示,“或”用“or”表示)
前面两个搜索语法还能混用
举例:滑盖手机 -site:www.taobao.com,指有关滑盖手机的页面,但排除掉淘宝
· “《搜索词》”搜索作品,而不是词语
· “intitle:搜索词”只显示标题中含搜索词的结果
注意:“:”是英文字符
举例:intitle:三体动画版,指标题中含三体动画版的内容
· “搜索词 filetype:格式后缀”搜索特定格式的文件
注意:“:”是英文字符
举例:简历模板 filetype:doc,指Word格式的简历模版”
人们的搜索习惯变了。但是目的没变。那就是缩短,提问和答案之间的时间。2012年,Google 打造“知识图谱”项目。意思是,所有事物都能组成一张关系网,当用户搜A,Google就把跟A“相关”的信息片段式呈现在结果页面上。直接片段式呈现目的是,让搜索引擎直接回答用户问题,而用户无须再点进链接看了。
Larry Page和Sergey Brin已经被Google召回,参与到公司业务中(就是曾经写PageRank算法的),Brin甚至亲自下场为Google聊天机器人写代码。
看来人们需要一个全新的信息获取手段,来取代传统搜索引擎,“就像搜索引擎杀死黄页一样”。
参考文献
[1] https://backlinko.com/hub/seo/ranking-factors
[2] https://arxiv.org/abs/2207.07330
[3] https://cloud.tencent.com/developer/article/1080811
[4] http://www.cjzzc.com/article/721.html
作者:温豪、沈知涵
编辑:沈知涵
,搜啥啥不行!迅读网 文心一言和GPT-4快救救搜索引擎吧相关:
英国千名医生罢工:工资不如卖咖啡,患者都支持我本文作者:黄桃鱼子酱在 2012 年奥运会开幕式上,上百张病床被搬到体育场中央,「护士」辛勤忙碌,「患者」床上翻飞,医生们组成「NHS」三个字母翩然起舞。在全场难以抑制的欢呼和掌声中,英国向全世界展示着他们引以为豪的全民免费医疗。在英国,NHS(国家医疗服务体系)是实力的象征。让「全民免费医疗」理念深入人心,被认为是和工业革命、莎士比亚和哈利波特一样对世界的贡献。2020 年,英国前首相 Boris Johnson 称赞..
伊朗第一夫人:我们习惯了吃苦,总比受辱好3月10日,中华人民共和国、沙特阿拉伯王国、伊朗伊斯兰共和国三方在北京发表联合声明,宣布沙特和伊朗达成协议,恢复双方外交关系,两国外长将举行会晤,探讨加强双边关系。在这一大背景下,《风云对话》不久前采访了伊朗总统莱希夫人贾米勒·阿拉姆·胡达,有助于我们了解这一事态的发展。1965年,贾米勒·阿拉姆·胡达出生于一个著名的、极端保守的牧师家庭。多年来,她一直在大学教授教育学,致力于从伊斯兰的角度审视社会问..
波提切利经典杰作将在上海展出 中新网上海3月16日电(王笈)记者16日获悉,“波提切利与文艺复兴”展览将于4月28日至8月27日亮相上海东一美术馆,展出波提切利以及其他文艺复兴艺术大师的共48件稀世真迹。 据介绍,此次展览是中国大陆迄今为止最大规模的波提切利主题展,多达10件桑德罗·波提切利的杰作将从意大利佛罗伦萨的乌菲齐美术馆来到上海。其中包括乌菲齐美术馆的“镇馆之宝”、波提切利的著名杰作《三博士朝圣》和《女神帕拉斯·雅典娜与半人..
光与影的视觉盛宴 全国各地300余件皮影在沪集中展出 中新网上海3月16日电(记者 许婧)“三尺生绢做戏台,全凭十指逞诙谐。有时明月灯窗下,一笑还从掌握来。”皮影艺人操纵由兽皮或纸板做成的人物剪影,搭配幕布和曲调,在戏台上唱尽人生百态。16日,“灯影中国:广宇长宙中的生活与想象”特展开幕仪式在上海大学博物馆举办。 展览现场。 上海大学供图 本次展览由上海大学博物馆(海派文化博物馆)与成都博物馆(成都中国皮影博物馆)联合策划举办。 陕西、河北、湖..
青海玉树各级非遗项目名录达280项 中新网西宁3月16日电(记者 李江宁)16日,记者从青海省文化和旅游厅获悉,目前,青海玉树藏族自治州各级非遗项目名录达280项,玉树州在传统美术、技艺、医药、民俗类项目数量多,将成为助力玉树地区乡村振兴、健康青海建设、文旅融合发展、打造国际生态旅游目的地的有力依托和重要载体。 近期,青海省人民政府印发《关于公布青海省第六批省级非物质文化遗产代表作名录的通知》,该省97项非物质文化遗产代表性项目获批..
上海高校食堂标准化菜谱发布 中国青年报客户端上海3月16日电(中青报・中青网记者 魏其鳎┙裉焐衔纾
北京地区首趟中欧班列开行 京平综合物流枢纽中欧班列宣传片。视频来源:平谷区委宣传部 中国青年报客户端北京3月16日电(中青报・中青网记者张敏)今天9时20分,一列满载汽车配件、建材、家电、铜版纸、布料、服装、家居等货物的中欧班列从北京平谷马坊站驶出。该班列是从北京地区首发的中欧班列,共55个40英尺集装箱,将经由满洲里铁路口岸出境,一路向西直达俄罗斯首都莫斯科。 此班列的开行意味着北京市外贸运输又多了一条横贯亚欧大陆的..
黄河封冻河段全线开河 中国青年报客户端北京3月16日电(中青报・中青网记者 高蕾)记者从水利部获悉,3月16日,黄河内蒙古河段全线开河,凌汛洪水安全进入万家寨水库,标志着黄河2022―2023年度防凌工作顺利结束。本年度黄河凌情总体平稳,全河未发生凌汛灾害。 2022年11月29日,黄河内蒙古三湖河口河段首次出现流凌,11月30日内蒙古三湖河口水文断面附近出现首封。至2023年1月30日全河达到最大封河长度985.69千米。2月初,受气温回升影响,..
吉林大部迎“珍贵”春雪 珍稀候鸟乘雪而归 中新网长春3月16日电 (郭佳 王凯)连日来,吉林省大部迎来春雪,结束了长达两个多月的“贫雪”状况。与此同时,大量南迁候鸟乘雪而归,拉开春季迁徙大幕。 年初以来,吉林省气温明显高于常年,降水也要比常年少三四成,还发生了沙尘天气。三月份第一周,当地有27个县市日最高气温突破了历史同期纪录。 飞越丛林的灰鹤。 潘晟昱 摄 据吉林省气象台介绍,当前这轮降雪天气始于3月14日,截至16日早上,全省平均..
甘肃省侨联“一带一路”法律研究与服务中心揭牌 中新网兰州3月16日电 (闫姣 九美旦增)16日,由西北师范大学与甘肃省侨联共建的甘肃省侨联“一带一路”法律研究与服务中心揭牌仪式在兰州市举行。 甘肃省侨联主席闫鹏勋说,针对甘肃企业在与“一带一路”沿线国家开展招商引资和经贸往来过程中遇到的有关法律问题、法律风险防范、相关维权机制建立等方面开展调查研究,该中心旨在为甘肃“一带一路”建设提供理论支持和法律保障,并打造成涉侨高层次法律服务与研究人才..